


It’s your first day at “TechTonic Innovations,” a (fictional) startup that’s been making waves in the tech industry. As you enter their modern office, you’re greeted with smiles, handshakes, and the subtle hum of servers in the background. You’ve been brought in as the new Data Strategist, and you’re eager to dive into the heart of TechTonic’s operations.
Your workstation is impressive, with high-res monitors and the latest tech gadgets. But what catches your attention is the access you’ve been granted to their data management system: a traditional database. At first glance, it seems straightforward. Rows and columns of data are neatly organized and categorized. But as you start to explore deeper, you sense the challenges ahead.
TechTonic is growing at an unprecedented rate. With every new product launch and market expansion, the volume and variety of data are skyrocketing. The traditional database, while reliable, is starting to show its limitations. You realize that as TechTonic scales, so will the complexity of its data challenges. And you’re right at the heart of it, tasked with guiding the company through the evolving landscape of data warehouses, lakes, meshes, and fabrics.
As you sip your coffee, you ponder the journey ahead. It will be a thrilling ride filled with decisions, innovations, and transformations. And you’re in the driver’s seat, steering TechTonic towards a data-driven future.
The Challenge of Scaling and Structured Analysis
The initial weeks at TechTonic are a blend of excitement and discovery. With the company’s rapid expansion, data pours in from every direction. But as the datasets grow, the limitations of the traditional database become glaringly evident.
One evening, as the sun casts a golden hue over the city, you find yourself in a deep discussion with Alex, TechTonic’s CTO. “We’re scaling faster than we anticipated,” Alex remarks, concern evident in his eyes. “Our current system, while reliable, isn’t equipped for this magnitude.”
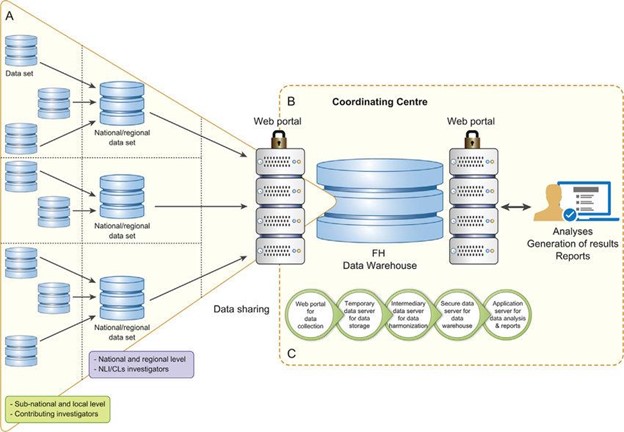
You nod in agreement, sharing your observations and the feedback from various teams. The conversation naturally gravitates towards a solution that’s been making waves in the data world: the Data Warehouse.
Ref: Researchgate
Unlike traditional databases, a data warehouse is a behemoth designed for heavy lifting. Here’s what sets it apart:
- Architecture & Design: At its heart, the data warehouse is a specialized database, but its architecture sets it apart. The Star Schema is like the solar system—a central fact table (the sun) surrounded by dimension tables (planets). It’s designed for swift queries. Then there’s the Snowflake Schema, a more intricate design where dimension tables are further detailed, ensuring efficient storage at the cost of slightly more complex queries.
- ETL Processes: Before data even steps into this grand structure, it is refined . The Extraction, Transformation, and Loading (ETL) process is like a meticulous gatekeeper, ensuring every piece of data is consistent and in its prime form.
- Data Integration & Consistency: Inside the warehouse, data from diverse sources come together, creating a Single Source of Truth. And with Data Cleansing, any off-note (inconsistencies or errors) is corrected, ensuring the analytics is pitch-perfect.
- Historical Data & Time-variant: The warehouse isn’t just about the present; it’s a time machine. With Time-stamped Data, you can journey back, analyzing trends and patterns. And with Snapshot Data, you can freeze moments, comparing them to see how far you’ve come.
- Aggregation & Performance: To ensure swift performance, data warehouses come with a trick up their sleeve. Pre-aggregated Data acts like a summary, offering quick insights. With techniques like Indexes & Partitioning, even the most intricate queries are a breeze.
- Scalability & Storage: As TechTonic’s ambitions grow, so does its data. But the warehouse is ready. With Massive Parallel Processing (MPP), tasks are divided and executed simultaneously across servers. And Columnar Storage ensures data retrieval is lightning-fast, storing data in columns rather than rows.
With this arsenal of features, TechTonic embarks on its data warehouse journey. The transformation is nothing short of revolutionary. Reports are generated in moments, analytics dive deeper than ever, and the entire company stands on a robust, data-driven foundation.
As you reflect on this transition, it’s clear that the data warehouse isn’t just a tool—it’s TechTonic’s compass guiding its voyage into uncharted innovation territories.
Diversifying Data and the Need for Flexibility
TechTonic’s success story isn’t just about growth in numbers; it’s about diversification. As you walk through the buzzing office, you see teams brainstorming new product ideas, marketing strategizing global campaigns, and customer support flooded with feedback from different corners of the world. The data pouring in isn’t just numbers; it’s videos, images, audio clips, and unstructured feedback.
One day, during a brainstorming session, Mia, the head of product development, shares an intriguing insight. “We’re getting design inspirations from user-uploaded images and videos. But where do we store this diverse data? Our current system isn’t cut out for this.”
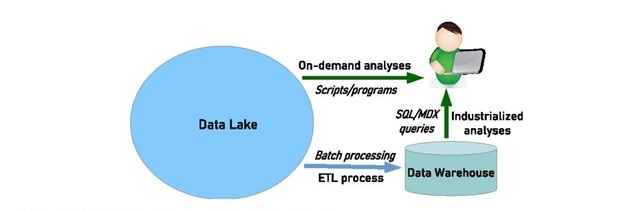
Enter the Data Lake.
Ref: arxiv
- Nature & Structure: Unlike the structured environment of a data warehouse, a data lake is like a vast ocean, accommodating data in its raw, natural form. Imagine a colossal reservoir where data flows in from countless streams, each with its unique properties. Whether it’s structured data from databases, unstructured data like videos, or semi-structured data like JSON and XML, the data lake embraces it all.
- Scalability & Storage: As TechTonic’s data sources multiply, the data lake’s scalable architecture ensures it’s always ready for more. Built on distributed systems like Hadoop, it can store petabytes of data without breaking a sweat. Think of it as a vast library with infinite shelves, ever-ready to accommodate more books.
- Schema-on-Read: One of the standout features of a data lake is its “schema-on-read” approach. Instead of defining a schema when data is ingested (as in traditional systems), the schema is applied when data is read for analysis. It’s like an artist with a block of marble, carving out a statue only when they have a clear vision.
- Data Processing & Analytics: With tools like Spark and Hive, the data lake isn’t just a storage solution; it’s an analytics powerhouse. Whether real-time processing or batch analytics, the data lake offers the flexibility TechTonic needs to glean insights from its diverse data.
Ref: arxiv
- Integration with Advanced Analytics: As TechTonic delves into advanced analytics, machine learning, and AI, the data lake seamlessly integrates with these platforms. It’s the perfect playground for data scientists, offering raw data for experimentation and model training.
With the implementation of the data lake, TechTonic finds itself equipped to handle the diverse data challenges of its expanding horizons. The teams can now dive deep into the lake, fishing out insights that drive innovation and cater to the ever-evolving needs of their global clientele.
As you sip your evening coffee, overlooking the city’s skyline, you realize the data lake isn’t just about storage; it’s about possibilities, a canvas for TechTonic to paint its future.
The Complexity of Decentralization & Data Ownership
TechTonic’s success isn’t just a linear trajectory upwards; it’s an expansive sprawl. New departments mushroom across floors, each with its distinct flavor and data appetite. The marketing team, with its dynamic campaigns, the R&D department diving deep into experimental data, and the sales team, with its ever-evolving metrics. The once unified data landscape now resembles a bustling metropolis, with each department as its borough, each with its unique rhythm and requirements.
During a leadership meeting, Serena, the head of the newly formed IoT division, raises a concern. “Our data needs are vastly different from, say, the e-commerce team. We need autonomy over our data, but also ensure it aligns with TechTonic’s standards.”
The room resonates with murmurs of agreement. The challenge is clear: How does TechTonic ensure data ownership, maintain quality, yet provide the flexibility each department craves?
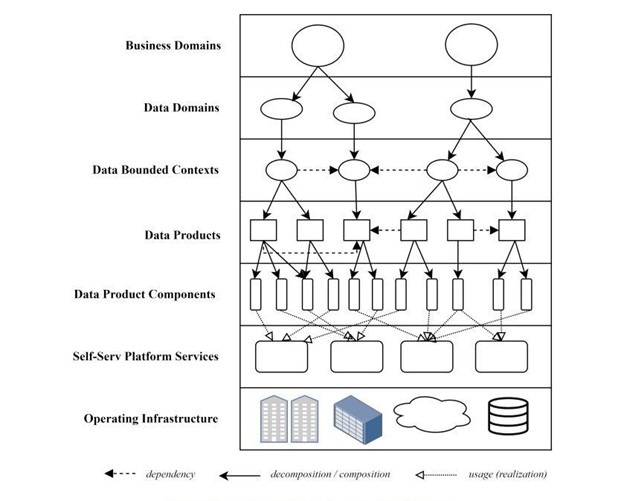
The answer lies in the Data Mesh.
Ref: arxiv
- Decentralized Data Ownership: Unlike traditional centralized data architectures, the data mesh paradigm shifts ownership to individual teams. Imagine each department as a mini-republic, governing its data yet adhering to the broader constitution of TechTonic. Each team becomes the custodian of its data, ensuring its quality and relevance.
- Data as a Product: In the world of the data mesh, data isn’t just an asset; it’s a product. Each data domain is treated with the same rigor as a product, with its lifecycle from inception to retirement. This philosophy ensures that data is always in its prime, ready for consumption for analytics, machine learning, or business intelligence.
- Self-Serve Data Infrastructure: Empowerment is at the heart of the data mesh. With self-serve data infrastructure, teams can access, process, and analyze data without hurdles. It’s like having a personal chef ready to whip up whatever dish you fancy whenever you crave it.
- Interoperability & Integration: While autonomy is crucial, the data mesh ensures seamless integration across domains. Standardized protocols and interfaces ensure data flow smoothly between departments, fostering collaboration and holistic insights.
TechTonic witnessed a renaissance in its data culture with the adoption of the data mesh. Departments, once siloed, now collaborate with renewed vigor. Data quality surges and innovation thrives, with each team taking pride in its data product.
As you stroll through TechTonic’s vibrant office, you can’t help but marvel at the harmony. The data mesh hasn’t just solved a technical challenge; it’s fostered a culture of ownership, pride, and collaboration. TechTonic, in its new avatar, is poised for greater horizons, with data as its guiding star.
Integrating Data Across the Ecosystem
TechTonic’s upward journey is nothing short of a blockbuster. From a fledgling startup to a tech behemoth, its growth is mirrored in its soaring stock prices and its intricate web of systems, applications, and partnerships. With every merger, acquisition, and new product launch, the data landscape becomes richer and more complex.
During an executive retreat, Lucia, the Chief Data Officer, presents the challenge. “We’re not just dealing with our internal systems. We have data flowing in from our partners, from the startups we’ve acquired, and from the new platforms we’re exploring. How do we weave these into a cohesive tapestry?”
The solution, as you all discover, lies in the Data Fabric.

Ref: freepik
- What is a Data Fabric?: At its core, Data Fabric is an advanced, integrated set of data services, architectures and connectors. It’s not just a tool but a comprehensive framework designed to ensure smooth data flow irrespective of the volume, type, or location of the data. It leverages modern technologies like AI and machine learning to automate and optimize data operations.
- Unified Data Architecture: This isn’t just about connecting different data sources. The architecture of data fabrics is designed to span on-premises systems, multiple cloud environments, and even edge devices. It uses advanced protocols and connectors to ensure that every data source, whether distinct or dispersed, is interconnected seamlessly. This architecture handles structured and unstructured data, from traditional databases to real-time IoT streams.
- Dynamic Data Integration: Traditional data integration methods often rely on batch processes, which can be static and lead to bottlenecks, especially with large data volumes. Data Fabrics, on the other hand, adopt a dynamic approach. It uses event-driven architectures and real-time processing capabilities, ensuring seamless and timely data movement across the entire ecosystem.
- Semantic Layer & Data Virtualization: The Data Fabric architecture’s semantic layer is more than a consistent data view. It provides a unified data ontology, ensuring data from different sources is interpreted and used consistently. This abstracts underlying complexities, making it easier for end-users to access and understand data. Data Virtualization is another feather in its cap. It provides real-time access to data without the need for physical movement or replication, reducing storage costs and ensuring up-to-date data access.
- Automated Data Discovery & Cataloging: As data sources grow, manually tracking them becomes nearly impossible. Data Fabric’s automated discovery uses AI-driven algorithms to scan, identify, and catalog every data source. It identifies the data and understands its context, relationships, and quality, updating this information in real-time.

Ref: freepik
- Security, Governance, & Compliance: An expanding data landscape brings myriad security challenges. Data Fabrics are built with a security-first approach. They incorporate end-to-end encryption, role-based access controls, and advanced threat detection mechanisms. Beyond security, they have built-in governance mechanisms, ensuring data quality, lineage, and lifecycle management. Regulatory compliance is not an afterthought; the system is designed to adhere to global standards, be it GDPR, CCPA, or HIPAA.
- Self-Service & Decentralized Access: Empowering teams is at the heart of the Data Fabric architecture. With intuitive interfaces and self-service capabilities, departments can access, process, and analyze data without always relying on IT. This fosters a culture of data democracy, where insights are democratized. However, this freedom comes with checks and balances to ensure data integrity and security.
The transformation is palpable as TechTonic integrates the data fabric into its infrastructure. Data silos crumble, insights flow freely, and teams collaborate with a renewed sense of purpose. The once-daunting challenge of integrating a diverse data ecosystem is now TechTonic’s strength, propelling it to new heights.
Key Takeaways: One Size Does Not Fit All
In the realm of data management, there’s no universal solution. Each architecture has its unique strengths, weaknesses, and ideal scenarios. As we explore each, remember that the best choice often depends on specific needs, budgets, and use cases.
Data Warehouse:
Strengths: A meticulously organized system, the data warehouse is like a grand library. Designed for query performance and analytic processing, it’s a star performer for business intelligence tasks where data structure and integrity are crucial.
Weaknesses: However, its structured nature means it’s less accommodating of unconventional data formats. Storing unstructured or semi-structured data isn’t its strong suit. Moreover, as data volumes grow, scaling can be a costly endeavor.
Best For: Organizations with well-defined analytic requirements and a primary focus on structured data.
Data Lake:
Strengths: Imagine a vast reservoir capable of holding a myriad of data types. That’s the data lake for you. Its strength lies in its flexibility, allowing for the storage of structured, semi-structured, or unstructured data without the constraints of a fixed schema.
Weaknesses: But flexibility can be a double-edged sword. Without proper management, data retrieval can become slower, and there’s a risk of the lake turning into a ‘data swamp’, where data becomes unmanageable and loses its value.
Best For: Organizations dealing with diverse data types and looking for a cost-effective storage solution.
Data Mesh:
Strengths: The data mesh philosophy is about empowerment. It decentralizes data ownership, allowing individual teams to treat their data domains as products. This ensures data quality, accessibility, and faster innovation.
Weaknesses: Decentralization brings challenges. Without a cohesive strategy, there’s a risk of data silos, where data becomes trapped in departmental bubbles, hindering organization-wide insights.
Best For: Large organizations with multiple departments having specific data needs, aiming for a more democratized data approach.
Data Fabric:
Strengths: Data fabric is the overarching framework, ensuring seamless data integration across diverse landscapes. It’s the connective tissue, ensuring data isn’t just stored but is also easily accessible, integrated, and processed across various environments.
Weaknesses: Implementing a data fabric architecture requires a comprehensive strategy, and without proper planning, it can lead to complexities in data management and integration.
Best For: Enterprises with multiple systems, applications, and a need for a unified data access and integration strategy.
As we reflect on these architectures, it’s evident that the right choice hinges on the specific challenges at hand. For a budding startup, a data warehouse might suffice, but as it evolves, diversifying its data sources, a data lake or data mesh might become more apt. And for those navigating the complexities of mergers and acquisitions, the data fabric offers a guiding light. The key is to understand the nuances and choose wisely.
Conclusion
Through the illustrative journey of TechTonic, we’ve ventured into the intricate world of data management. From the imagined early days of a startup grappling with structured analytics to the complexities faced by a large-scale enterprise, TechTonic’s narrative serves as a metaphor for the challenges many organizations face.
The crux of our tale? Data management isn’t static. As organizations grow and evolve, so do their data needs. And while TechTonic may be a fictional entity, the lessons it offers are very real: understanding the nuances of each data solution and choosing the right approach at every juncture is paramount. In this ever-evolving data landscape, adaptability, knowledge, and strategic decision-making remain our guiding stars.