


TORONTO, March 15, 2022:
Scribble Data, an ML feature engineering startup today announced that it has raised $2.2 million in seed funding led by Blume Ventures. The round also saw participation from Log X Ventures and Sprout Venture Partners, in addition to participation from Vivek N. Gour (former CFO, Genpact) and Ganesh Rao (Partner, Trilegal).
Scribble Data, has been in the business of reducing friction in the data science lifecycle. A significant theme for the team was around trustworthiness in how data is prepared for ML and data science. In 2019, Scribble Data narrowed their focus to building a feature engineering platform.
Scribble Data’s Enrich feature store is a collection of ‘apps’ that streamline the feature engineering lifecycle to train ML models. These apps include a core versioned pipeline orchestrator with pluggable engines, a feature marketplace, a metadata service, a profiler and automatic visualizer, a compliance service and a metrics store app, among others. Enrich’s modular design allows data teams to integrate these apps into their existing data tech stacks, as well as to build their own feature engineering apps to streamline the feature engineering process in their specific context.
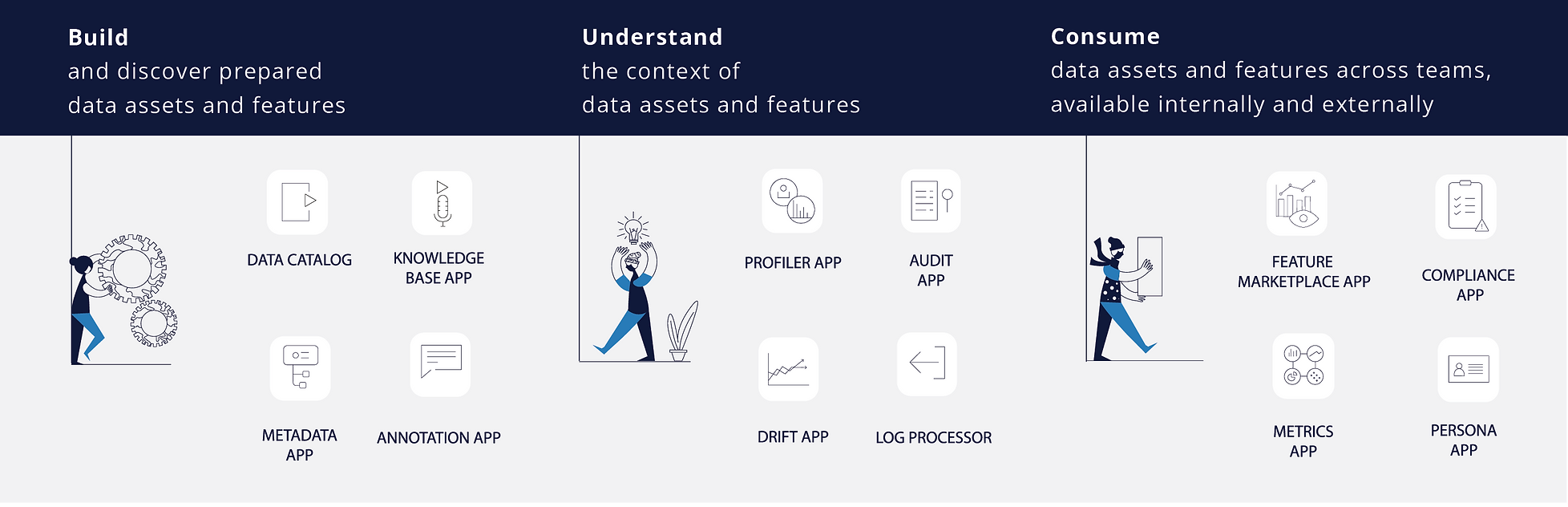
Enrich Modular Feature Store
Enrich helps data teams cut time-to-production for each machine learning model or sub-ML use case that requires the complex transformation of raw data at scale. Enrich streamlines the building of “features” (derived attributes of data) complete with rich lineage and auditability. This not only allows data teams to collaborate on these rich datasets, but to do so with a high degree of trust in how the data has been transformed across multiple steps. Scribble has customers in FinTech, E-commerce, Edtech and Healthcare.
This seed round will be used to build out Scribble’s product roadmap, and to build a strong presence for Scribble Data in the North American market as they grow their customer base. The product roadmap includes a low code consumption interface for teams to access and use features produced on the platform, as well as additional apps that bring data teams closer to specific solutions like anti-money laundering, benchmarking, personalization, and recommendations, among others.
Scribble Data will also use the new capital towards strengthening their integration with third party data solutions, like Redis. Commenting on their collaboration with Scribble Data, Taimur Rashid, Chief Business Development Officer for Redis said, “Collaborating with Scribble Data’s Engineering team, we successfully deployed Redis’ high-performance entity matching solution for a joint customer where Enrich handled integration with multiple data sources, data prep pipelining and orchestration, as well as batch and streaming feature engineering. Using Redis’ in-memory vector similarity lookup, Enrich achieved a ~30x speedup on entity match generation. This opens more ways for developers and organizations to use Redis’s capabilities for machine learning use cases, so we’re looking forward to working closely with Scribble Data to address customers’ machine learning workloads.”
“With this fundraise, we will be doubling down on hiring the right talent to help deepen the Enrich feature store, as also to ensure world class product support for our customers,” said Indrayudh Ghoshal, co-founder, Scribble Data. He further added, “The problems of data lacking consistency, context, and credibility are fairly common. We’ve seen great organic growth over the last year, and this fundraise will help us address the growing interest in our platform.”
Anirvan Chowdhury, VP, Blume Investment team said “With more organizations effectively becoming data companies, there is a proliferation of high quality, compliant feature sets for ML and Sub-ML use cases in an organization. And those feature sets will need to be managed, re-used and served in the most effective manner into ML models or other Sub-ML use cases.”
He further added, “We’re excited to back Scribble Data, whose novel approach to hard problems in deep tech will serve a wide variety of use cases for global markets. We particularly liked Scribble Data’s modularized Feature Store approach and an App Store with the Enrich Feature Store as a backbone to solve for end to end use cases. The market is in its early stages, but we believe it will expand significantly with applications being built on top of the Feature Store and are super excited to be a part of this journey.”
About Scribble Data
Scribble Data is an MLOps product company. Their modular feature store, Enrich, comprises a number of pre-built feature engineering apps to help data teams cut time-to-market for each data science use case including unified metrics, customer behavioral modeling, and recommendations. Enrich streamlines the data prep process with versioned pipelines, delivering continuously updated data through intuitive interfaces and surfacing context around datasets via extensive metadata and lineage tracking. With offices in Toronto and Bangalore, Scribble Data has clients across 4 continents. To know more about Scribble Data, follow us on LinkedIn, and Twitter or visit us at www.scribbledata.io