


The titans of industry are in an AI arms race. They’re not waiting for solutions. They’re building them.
They are on the front lines – with foundational models, intricate ML systems and computing services that serve their sprawling global ambitions. Others are arming themselves too. With cloud platforms, engineering solutions and homegrown AI.
Before our eyes, the landscape of global commerce and the rules of business are being rewritten in real-time. With every line of code and every trained model. This, then, is the state of enterprise AI adoption—a no-holds-barred race to the future where the prize is market dominance and the cost of entry is measured in billions.
Enterprise AI Adoption @ UBER
Uber revolutionized transportation, but its ambitions don’t stop there. The company that taught the world to hail rides with a tap is now harnessing AI to transform its entire operation. From customer support to data management, Uber’s applying its disruptive spirit to artificial intelligence.
LLMs @ Uber
Uber has embarked on an ambitious journey to harness the power of LLMs across a vast array of operations. The company identified over 60 distinct use cases for LLMs, ranging from process automation to customer support. Initially, the lack of a unified approach led to inefficiencies.
The Michelangelo team at Uber rose to this challenge by developing the GenAI Gateway. This innovative platform serves as a centralized hub for all LLM operations within the company, offering seamless access to models from various vendors like OpenAI and Vertex AI, as well as Uber’s own hosted models.
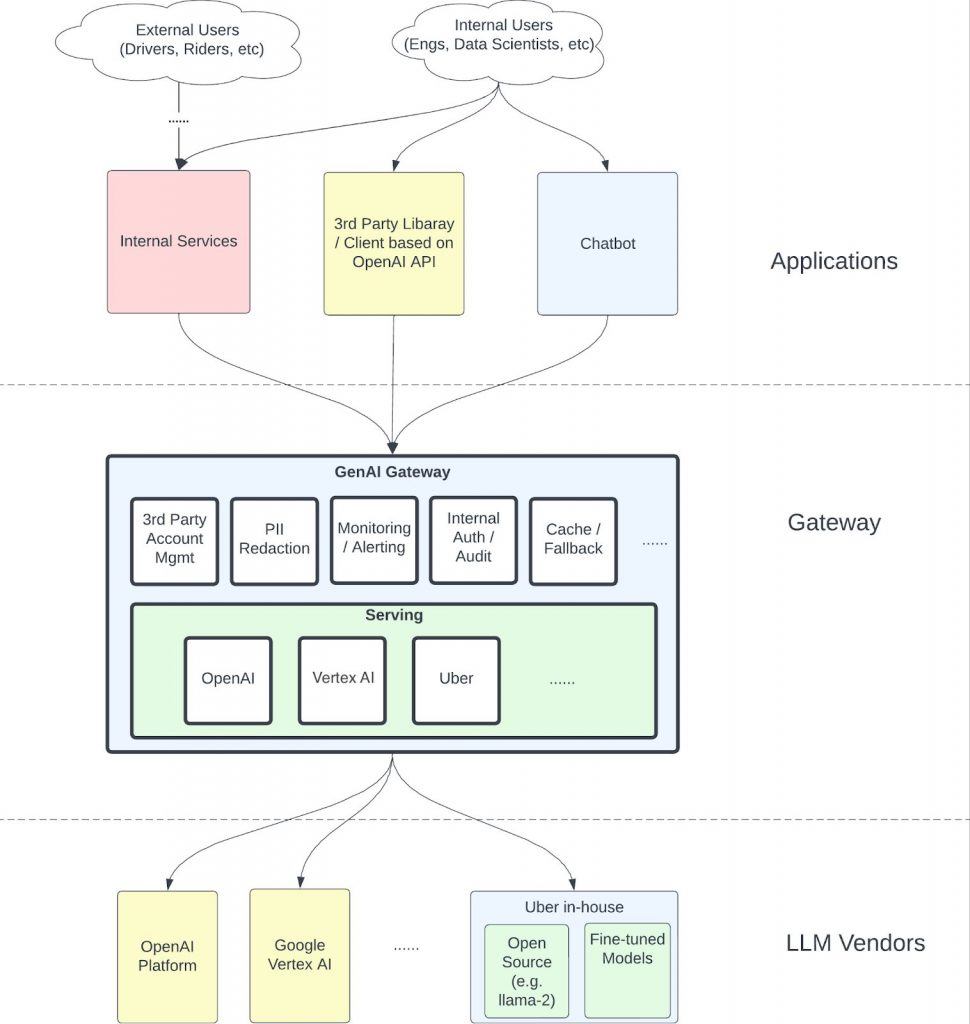
Built as a Go service, it mirrors the interface of the popular OpenAI API, ensuring compatibility with existing tools and libraries. This design choice allows Uber to stay in step with the rapidly evolving open-source community while providing a familiar environment for developers.
But the team didn’t stop at just creating an interface. They went a step further by developing their own implementations where necessary. For instance, when faced with the absence of a suitable Go implementation for accessing PaLM2 through Vertex AI, the team took the initiative to create their own and later open-sourced it.
The GenAI Gateway incorporates a sophisticated PII (Personal Identifiable Information) redactor, which anonymizes sensitive data before it reaches third-party vendors. This feature demonstrates Uber’s unwavering commitment to protecting user data, although it does introduce some latency.
The impact of this AI integration is perhaps most visible in Uber’s customer support operations, where
- LLMs are used to summarize customer issues and suggest resolution actions.
- 20 million summaries are generated per week.
- 97% of these summaries prove useful in resolving customer issues.
Today, the GenAI Gateway serves as the backbone of Uber’s AI operations, being used by nearly 30 customer teams and processing 16 million+ queries monthly.
Cloud Platforms @ Uber
Uber deals with massive amounts of data – we’re talking about hundreds of petabytes (that’s millions of gigabytes). This data includes everything from ride information to user feedback and much more.
In its infancy, Uber relied on traditional databases like MySQL and PostgreSQL. However, as the company expanded rapidly across cities and countries, these systems quickly proved inadequate for handling the sheer volume and complexity of data pouring in.
To address this challenge, Uber transitioned to a Big Data platform built around Apache Hadoop. This powerful open-source framework allowed them to store and process massive amounts of data across clusters of computers. The Hadoop-based system served as the backbone of Uber’s data infrastructure for several years, enabling them to
- Store tens of petabytes of data
- Run over 100,000 Spark jobs and 20,000 Hive queries daily.
- Support thousands of city operations team members and hundreds of data scientists
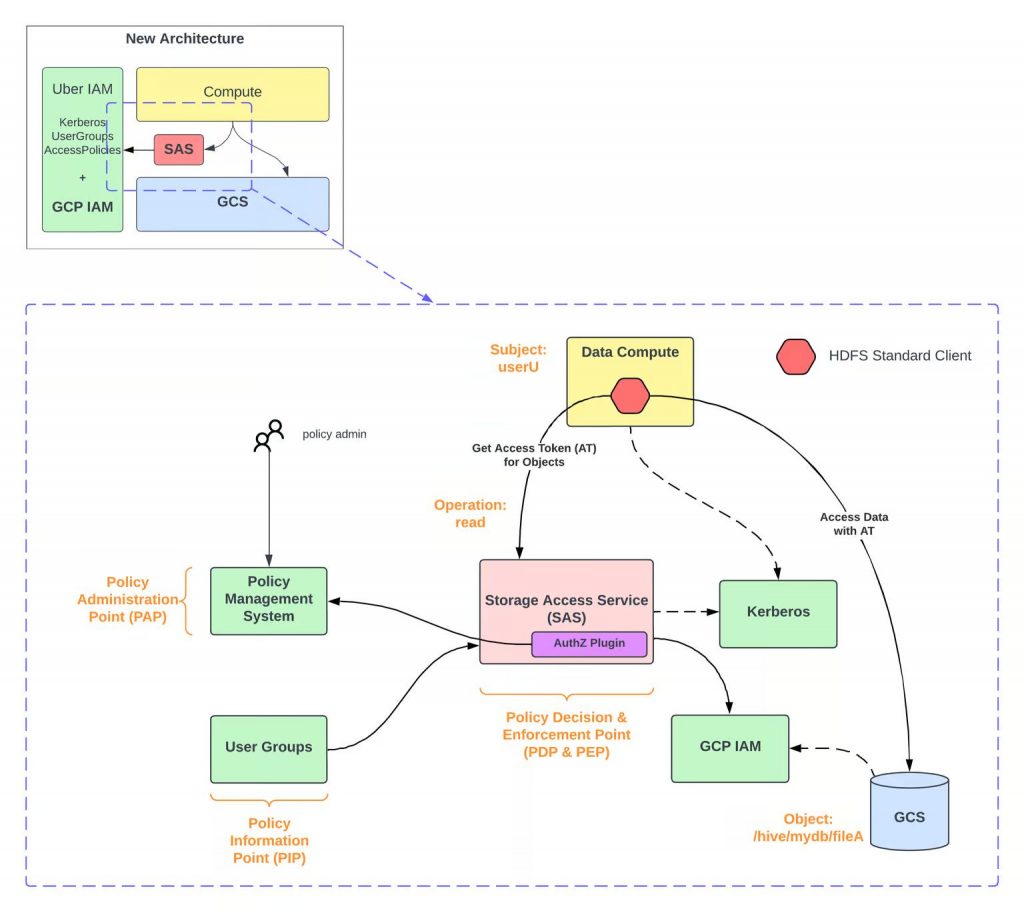
Uber is gradually migrating their massive data infrastructure to the cloud, specifically the Google Cloud Platform. This migration involves
- Replacing HDFS (Hadoop Distributed File System) with Google Cloud Storage (GCS)
- Running data processing tools like Apache Spark, Presto, and Hive on Google Compute Engine
Engineering Platforms @ Uber
Two of the key platforms that power Uber’s sprawling internal operations are Up and Odin. They play crucial roles in managing the company’s vast array of services and data.
Up
Up is Uber’s solution for managing its army of microservices – over 4,500 small, independent pieces of software that work together to run Uber’s operations. Up is like a super-smart traffic controller for these services, ensuring they’re deployed correctly, run efficiently, and can be moved around easily when needed.
The key features of Up are.
- Automating service deployment, reducing manual work for engineers
- Managing where services run, allowing easy movement between different data centers or cloud providers
- Ensuring services are “portable,” meaning they can run anywhere without issues.
- Coordinating updates and changes across thousands of services simultaneously
This platform has been crucial in Uber’s transition to cloud computing, allowing the company to move services between its own data centers and cloud providers like Google and Oracle without disrupting operations.
Odin
While Up manages Uber’s microservices, Odin takes care of the company’s vast data storage needs. It’s a librarian for Uber’s digital information, managing everything from traditional databases to advanced data processing systems.
Odin’s key responsibilities are
- Managing over 300,000 data storage workloads across 100,000+ computers
- Supporting 23 different types of data technologies
- Automating the maintenance and operation of data storage systems
- Ensuring data is always available and properly backed up.
- Optimizing how data is stored to save on hardware costs.
Odin’s design allows it to handle an enormous amount of data while keeping everything running smoothly.
Enterprise AI Adoption at NVIDIA
Nvidia thrives at the bleeding edge of technology. With their roots in graphics processing, they’ve become the bedrock of modern AI infrastructure. Nvidia’s innovations touch everything from autonomous vehicles to drug discovery. Their approach to enterprise AI isn’t just ambitious—it’s reshaping entire industries.
LLMs @ Nvidia
ChipNeMo: Nvidia has developed a custom LLM called ChipNeMo, specifically designed for internal use in semiconductor design. This model is trained on Nvidia’s proprietary data and is utilized to generate and optimize software, assist human designers, and automate various tasks within the chip design process.
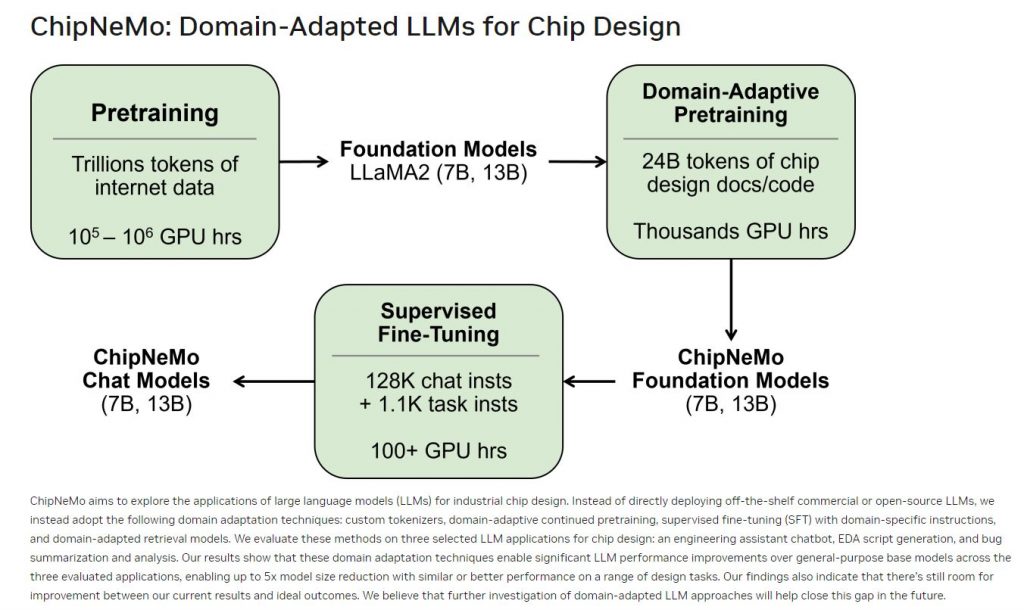
It features 7B and 13B models and has been trained on over a trillion tokens, enabling it to understand complex patterns in data. Initial applications include a chatbot for technical inquiries, a code generator for specialized programming languages, and an analysis tool for maintaining bug documentation.
NeMo Megatron: Nvidia also utilizes the NeMo Megatron framework for building and training large language models. This framework allows enterprises to create domain-specific models and has been instrumental in developing models like Megatron 530B, which can be customized for various applications.
NeMo Megatron automates the training process and supports efficient data handling, making it suitable for large-scale AI applications.
Cloud Platforms @ Nvidia
A key component of Nvidia’s cloud infrastructure is the Nvidia Inference Microservices (NIMs), which serve as APIs for AI applications. NIMs allow users to create applications by accessing data, LLMs, programming tools, and dependencies, simplifying interactions with AI models.
Nvidia utilizes Kubernetes for container orchestration, essential for deploying and managing AI models and applications in a cloud-native environment. All pre-trained proprietary and open-source LLMs are stored in containers optimized for GPU performance, enhancing model inference and deployment efficiency.
Additionally, Nvidia leverages its own cloud infrastructure, including customizable virtual machines that allow developers to run applications tailored to their specific needs.
The company employs a hybrid cloud strategy, integrating both on-premises and cloud resources to optimize performance and flexibility. This enables Nvidia to manage sensitive data securely while leveraging the scalability of public cloud resources for less sensitive workloads. Nvidia collaborates with major cloud providers such as Amazon Web Services (AWS) and Microsoft Azure, enhancing its cloud capabilities.
Nvidia also operates its own data centers equipped with high-performance computing resources tailored for AI workloads like training and deploying LLMs.
Engineering Platforms @ Nvidia
Nvidia’s programming model, CUDA, is foundational to its tech stack, enabling high-performance computing across various applications. CUDA-X AI is a complete deep learning software stack for researchers and software developers to build high-performance GPU-accelerated applications. It includes libraries and tools for training and inference across frameworks like PyTorch, TensorFlow, and JAX.
The Nvidia software stack integrates with popular frameworks, providing GPU-accelerated libraries such as cuDNN and TensorRT to enhance performance. The Nvidia GPU Cloud (NGC) catalog offers containerized frameworks and pre-trained models, allowing developers to quickly access optimized tools for their projects.
Enterprise AI Adoption at SALESFORCE
Salesforce is all about connections. In the world of AI, they’re connecting dots others don’t see. Their XGen model and Einstein AI platform are transforming CRM. With cloud partnerships and a robust engineering toolkit, Salesforce is leading from the front.
LLMs @ Salesforce
XGen is a 7B parameter foundational LLM built by Salesforce. It serves as the primary source used by Salesforce AI teams, who adapt, fine-tune and pretrain it to create customized, safe models for distinct domains and use cases across sales, service etc.
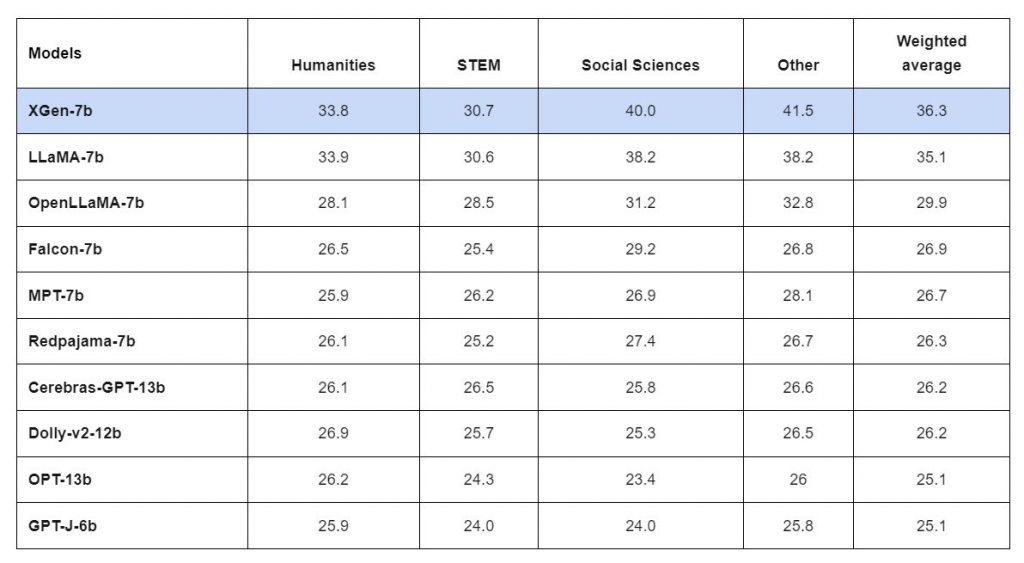
Since XGen is a smaller-scale model built primarily to serve Salesforce use cases, it is computationally efficient and able to maintain stringent data privacy protocols. This is particularly necessary for BFSI applications, where it is impractical to share sensitive information with third-party LLMs.
Previously, Salesforce operated five different legacy AI stacks, which led to challenges in delivering a cohesive narrative about features and compliance across geolocations.
The new Einstein AI platform consolidates multiple AI capabilities into a single framework, allowing for the reuse of features across various clouds and applications. This means that innovations developed for one area (such as call summarization) can now be leveraged across sales, marketing, and service applications without duplicating efforts.
generative AI capabilities. The integration of the Large Language Model (LLM) Gateway was crucial for supporting these workloads. This gateway allows for request routing to multiple in-house and external LLM providers, functioning as a microservice within Salesforce’s ecosystem.
This unified platform enhances the user experience for both internal teams and external customers.
Cloud Platforms @ Salesforce
Salesforce has had a long-standing partnership with AWS as their primary cloud provider. Here’s a brief history of how this relationship has deepened over the years.
- 2016: Salesforce designates AWS as its preferred public cloud infrastructure provider, enabling Salesforce to leverage AWS’s global cloud infrastructure for its core services.
- 2017: Salesforce and AWS integrate their platforms, allowing customers to use Salesforce’s CRM capabilities alongside AWS’s cloud services.
- 2018-2019: Salesforce and AWS announce a joint innovation partnership, integrating AWS’s AI and machine learning services, such as Amazon SageMaker, into Salesforce’s Einstein AI platform.
Source: AWS YouTube
- 2020-2021: Salesforce expands its use of AWS services, including Amazon Redshift for data warehousing and Amazon Kinesis for real-time data processing.
- 2022-24: The ecosystem is strengthened, with integrations of Salesforce’s Tableau and Mulesoft platforms with AWS services.
Salesforce has also had a strong collaboration with Google Cloud as a strategic infrastructure provider. The partnership began in 2017, with Salesforce selecting Google Cloud as a preferred public cloud provider to support its international infrastructure expansion.
Source: Google Cloud and Salesforce’s Framework for Enterprise Intelligence
Over the years, more and more services have been integrated with the Google Cloud Platform, such as combining Salesforce’s CRM capabilities with Google Analytics 360. In recent years, Salesforce has integrated Google Cloud’s AI services into their Einstein AI platform. Google Cloud services such as BigQuery and Dataflow have also been integrated into Salesforce’s Customer 360 platform.
Engineering Platforms @ Salesforce
Salesforce has a global, diverse workforce comprised of multiple teams that are working on cutting-edge development and problem-solving. To allow each of these engineering teams to foster a micro-culture of working and still maintain status quo on an organizational level, various tools have been added to the arsenal.
- Grand Unified System (GUS) is an internal application built on Salesforce that manages bugs, tasks, and releases, helping teams track product development and customer issues efficiently.
- Postman is essential for API development, providing organized collections and simplified authentication, which streamlines the development process.
- Salesforce Workbench is a web-based tool for managing and testing Salesforce data and APIs, appreciated for its speed and convenience in demos and debugging.
- Platform Operation Dashboard provides real-time monitoring of key performance metrics for Salesforce services, crucial for meeting service level agreements (SLAs).
- Buildkite is a scalable CI/CD platform that automates testing and deployment, allowing teams to manage code complexity effectively.
- FedX Managed Releases is an internal tool that streamlines the deployment of new features, reducing DevOps workload and enhancing operational efficiency.
- Einstein CodeGenie is an AI assistant that helps developers write code, detect errors, and auto-complete code blocks, improving productivity during development.
- Mermaid Chart is a markdown-like language that simplifies creating diagrams in documentation, enhancing communication and understanding of complex ideas.
- Streamlit is an open-source framework that accelerates the creation of interactive dashboards and web apps, particularly beneficial for machine learning engineers.
- Sloop tracks Kubernetes resources over time, facilitating debugging and enhancing productivity by visualizing resource lifecycles.
- IntelliJ IDEA is a software development IDE that offers intelligent coding tools, significantly enhancing coding efficiency.
- Amazon SageMaker simplifies the data preparation, model building, training, and deployment processes for machine learning projects, allowing teams to focus on solving customer problems.
NYSE’s Enterprise AI Adoption and Cloud Strategy
The New York Stock Exchange (NYSE), as the world’s largest capital market, processes billions of transactions daily, with record volumes reaching half a trillion messages. This massive ecosystem generates an enormous amount of data, presenting both challenges and opportunities for analysis and management.

Source: AWS YouTube
Before migrating to AWS cloud services, NYSE grappled with limited compute and storage capabilities, making it difficult to analyze all aspects of transactions. This move resolved many day-to-day operational challenges and allowed the exchange to shift its focus towards advanced analytics and machine learning.
Since the move to AWS Cloud, NYSE has been actively involved in LLM and AI initiatives company-wide. They’ve turned to Amazon Bedrock to test and deploy various generative AI models for their use cases. The exchange is heavily investing time and resources to understand generative AI not just from a technological standpoint, but also considering compliance and performance aspects.
One notable project is the Trading Rules Document Intelligence Chatbot. This tool is built using 20,000 pages of rules from all US exchanges, making complex trading regulations more accessible and user-friendly.
Another initiative is the Document Intelligence Tool, aimed at improving the efficiency and productivity of tech talent by addressing the challenges of understanding complex terminology often found in legal and financial documents.
The exchange is also developing a news sentiment analysis tool using LLM models. This system summarizes raw news feeds and performs sentiment analysis to predict potential stock price movements based on the news. The integration with Amazon Bedrock has enabled rapid validation of ML models, implementation of fine-tuning and Retrieval-Augmented Generation (RAG) techniques, and flexible testing and comparison of different models.
Enterprise AI Adoption at LYFT
Lyft isn’t just about getting you from A to B. Behind the scenes, their LyftLearn platform is driving AI innovation. From price optimization to fraud detection, Lyft’s in-house ML models are making millions of decisions daily.
Lyft’s Internal Approach to LLMs and ML Models
Lyft has developed a comprehensive Machine Learning Platform called LyftLearn, which encompasses model serving, training, CI/CD, feature serving, and model monitoring systems. This platform allows Lyft to build and maintain a wide variety of ML models in-house, tailored to their specific needs.
Lyft emphasizes a rigorous machine learning lifecycle, from prototyping to production and maintenance. They’ve created a uniform environment for training and serving models, ensuring reproducibility and development velocity. Their approach includes LyftLearn Serving for model hosting, automated CI/CD pipelines for retraining and deployment, and various monitoring techniques such as feature validation, model score monitoring, performance drift detection, and anomaly detection.
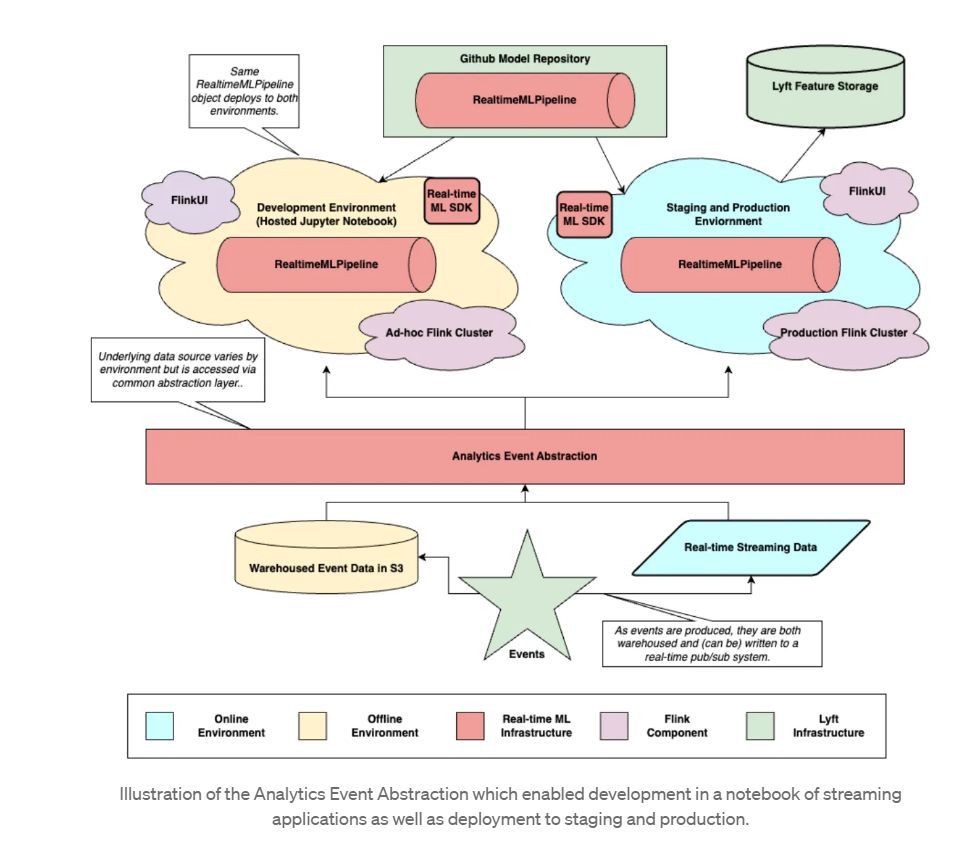
Lyft chooses to build in-house models over using external services for several reasons – customization, data privacy, scalability, deep integration with existing systems, and potential cost-effectiveness at their scale.
Cloud Platforms @ Lyft
Lyft has been using AWS since its inception in 2012, starting with just three servers in US East and growing to become a billion-dollar business by 2015. Throughout Lyft’s growth, AWS cloud services have played a crucial role in supporting their expansion and technological needs.
- EC2 and Auto Scaling: Enabled Lyft to handle rapid growth, including launching in 24 cities in 24 hours.
- DynamoDB: Simplified scaling for Lyft’s ride location tracking system.
- Redshift: Powered data analysis for the development of Lyft Line, their shared ride service.
- Kinesis: Facilitated communication between Lyft’s microservices through a pub-sub system.
Lyft uses hundreds of microservices on AWS processing millions of requests per second. The company also uses Google Cloud’s Maps Platform to improve the experience for riders and drivers.
Engineering @ Lyft
At the core of Lyft’s engineering infrastructure lies LyftLearn Serving, a powerful platform designed to handle the company’s vast machine learning needs. This system enables Lyft to make hundreds of millions of real-time decisions daily, powering critical internal operations that (while invisible to customers) are essential to Lyft’s smooth functioning.
The key features of LyftLearn Serving are as follows.
- Microservice Architecture: LyftLearn Serving is built on a microservices model, allowing for flexible and scalable deployment of ML models across Lyft’s infrastructure.
- Isolation and Ownership: Each team at Lyft gets its own isolated environment within LyftLearn Serving, enabling independent development, deployment, and management of ML models.
- Automated Configuration: A config generator simplifies the setup process, allowing ML modelers to quickly create and deploy new services without deep infrastructure knowledge.
- Customizable Model Serving: Teams can inject custom code for loading and predicting with their models, providing flexibility for various ML use cases.
- Robust Testing: Built-in model self-tests ensure the correctness and compatibility of models throughout their lifecycle.
LyftLearn Serving powers a wide array of internal use cases, including
- Price optimization for rides
- Driver incentive allocation
- Fraud detection
- ETA prediction
This platform allows Lyft’s teams to focus on developing and improving ML models rather than worrying about the complexities of deployment and scaling.
Conclusion
Large organizations are rapidly adopting AI and LLMs across sectors. They’re developing custom AI platforms instead of relying on off-the-shelf solutions. This enables tailored applications, better data privacy, and smoother system integration.
AI adoption is transforming entire organizations. It’s impacting multiple business functions, from customer service to product development. This requires significant investment in infrastructure and talent. It also demands a rethinking of organizational processes. For these enterprises, AI is key to future success.
For enterprises yet to start their AI journey, the time to act is now. The AI frontier is wild and unforgiving. Identify high-impact use cases in your organization. Start small. Scale fast. Build a core team of AI engineers and data scientists. They’re essential. Evaluate cloud providers. AWS, Google Cloud, Azure – choose your platform. It matters. Develop a modular AI architecture.
Iterate rapidly. Learn from failures. Adapt, or get left behind.
Do check out Carver Agents’ RegWatch – our new AI solution for real-time contextual regulatory risk intelligence, built for risk and strategy executives. Think of it as agentized mid-market LexisNexis. Visit https://carveragents.ai/.