


Picture this: You’re in the world of “Inception,” Christopher Nolan’s cinematic masterpiece. Dream architects are crafting intricate labyrinths within dreams, creating realities so convincing that the dreamer can’t tell they’re asleep. They are bending the fabric of the dream, shaping it to their will, whether it’s a heart-pounding chase through a bustling market or a clandestine meeting in a high-end dining room.

image source: https://www.freepik.com/free-ai-image/glowing-sine-waves-create-futuristic-backdrop-design-generated-by-ai_42586813.htm
Now, let’s swap out those dream architects for data scientists, and those dream worlds for synthetic data. That’s right, synthetic data. It’s not real, but it is so damn convincing that it can stand in for the real thing. It is a world meticulously crafted by data scientists, who, like the architects in “Inception,” use advanced algorithms and machine learning techniques to create diverse scenarios, manipulate variables, and generate data points that serve their specific needs.
In this article, we are going to pull back the curtain on synthetic data. We will explore its creation, its uses, its benefits, and its challenges. We will look at how it is making waves in various industries and how it is shaping the future of artificial intelligence. Just as the dream architects in “Inception” manipulate dreamscapes to achieve their goals, we’ll see how synthetic data is reshaping the landscape of data science, offering a flexible and powerful tool to overcome traditional data constraints.
So, grab a coffee, sit back, and prepare to go a layer deeper. We’re about to venture into the realm of synthetic data, where reality can be constructed, manipulated, and used to drive innovation in artificial intelligence. It’s going to be one hell of a ride.
Crafting Synthetic Data: A Technical Perspective
image source: https://www.freepik.com/free-ai-image/glowing-sine-waves-create-futuristic-backdrop-design-generated-by-ai_42586813.htm
Creating synthetic data is a process that requires precision, creativity, and a deep understanding of the underlying system. It is not unlike the meticulous work of the dream architects in “Inception,” but instead of dreams, we are dealing with data. Let us explore the technical side of some of these techniques.
Data Augmentation: In machine learning, particularly in tasks involving image, audio, or text data, data augmentation is a technique used to increase the size and diversity of the training data without collecting new data. A popular method in image generation is the “Random Erasing” technique. It randomly selects a rectangle region in an image and replaces its pixels with random values, introducing variations that help models become more robust and generalizable.
Generative Adversarial Networks (GANs): GANs are a class of artificial intelligence algorithms used in unsupervised machine learning. They consist of two neural networks—the generator and the discriminator—that are trained together. The generator creates new data instances, while the discriminator distinguishes between real and synthetic data. Over time, the generator learns to produce data that is almost indistinguishable from the real data. A notable example is “StyleGAN”, a variant of GANs developed by NVIDIA, which introduces a new generator architecture that controls the styles of the generated images at different levels of detail.
Variational Autoencoders (VAEs): VAEs are a type of autoencoder, a neural network used for data encoding. They learn a latent variable model for the input data, allowing them to not only encode data but also generate new data that is similar to the training data. “IntroVAE” is a variant of VAEs that can generate high-quality images and is capable of disentangling the latent representations, separating out the factors that contribute to the variations in the data.
SMOTE (Synthetic Minority Over-sampling Technique): SMOTE is a technique that addresses class imbalance by creating synthetic samples of the minority class. It operates in ‘feature space’, generating new instances by interpolating between the feature vectors of existing instances. A variant of SMOTE, “Borderline-SMOTE”, generates synthetic examples in the borderline and noisy regions, helping to balance out imbalanced datasets and improve the performance of machine learning models on minority classes.
Agent-based modeling: Think of a bustling city, with each individual, each group, and each organization acting as an autonomous “agent”. Each agent interacts with others and with their environment according to predefined rules. Now, imagine capturing all these interactions, all these actions in a computational model. This is agent-based modeling, a type of computational modeling that simulates the actions and interactions of these agents to assess their effects on the system as a whole.

image source: https://www.freepik.com/free-photo/high-angle-pie-chart-with-cities_32677519.htm
It is like watching a city from a bird’s eye view, observing the patterns, the chaos, and the order. The output of these simulations is a form of synthetic data that can be used to study complex systems and phenomena, offering a window into the intricate dynamics of our world.
Monte Carlo Simulation: In the world of synthetic data generation, randomness is not an enemy but a tool. Monte Carlo simulation is a technique that uses this tool to solve deterministic problems. It is like rolling a dice a million times to predict the outcome of a single roll. In the context of synthetic data generation, Monte Carlo simulations generate synthetic datasets that reflect the probabilistic behavior of a real-world system. It’s a way of exploring all possible outcomes and their associated probabilities, providing a comprehensive picture of potential scenarios. It is not just about predicting the future; it’s about understanding the range of possibilities.
The synthetic data generated by these techniques is not “real” in the sense of being collected from the real world, but it is “realistic” in the sense of accurately reflecting the behavior of the system being modeled. This makes it valuable for studying complex systems, testing hypotheses, and making predictions.
The Many Uses of Synthetic Data
Synthetic data is a chameleon, changing its form to suit the needs of a wide array of applications. From training AI/ML models to managing test data, from visualizing complex analytics to sharing enterprise data, synthetic data is the secret sauce that makes it all possible. Let us take a closer look at these applications.
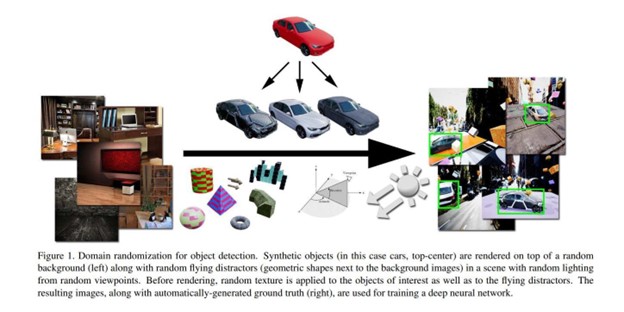
image source: https://openaccess.thecvf.com/content_cvpr_2018_workshops/papers/w14/Tremblay_Training_Deep_Networks_CVPR_2018_paper.pdf
AI/ML Training and Development: In the world of AI and ML, data is king. But not just any data. We need high-quality, diverse data that covers a wide range of scenarios and use cases. And that’s where synthetic data comes in. It allows us to generate large volumes of data tailored to our specific needs, making our models more robust, accurate, and generalizable.

image source: https://arxiv.org/pdf/1909.11512.pdf
This means we can train models to recognize patterns and make predictions with greater precision, even when faced with scenarios they haven’t encountered before.
Test Data Management: When it comes to testing, synthetic data is a game-changer. It allows us to create high-quality, diverse, and representative data for testing and validation. This means we can improve our testing processes, speed up our time-to-market, and reduce the costs associated with traditional test data management. By using synthetic data, we can simulate a wide range of test scenarios, ensuring our systems are robust and reliable before they’re deployed.
Data Analytics & Visualization: Synthetic data is also a powerful tool for data analytics and visualization. It allows us to create datasets tailored to specific applications or edge cases, improving the accuracy of our analysis and the quality of our visualizations. With synthetic data, we can model complex scenarios, visualize trends and patterns, and gain deeper insights into our data, all while maintaining privacy and security.
Enterprise Data Sharing: In an era of data privacy regulations, synthetic data provides a way for enterprises to share and collaborate on data without exposing sensitive information. It is like a mask that allows us to work with data without revealing its true identity. This means businesses can collaborate on data-driven projects, share insights, and innovate together, all without compromising data privacy.
Industry-Specific Use Cases: From healthcare to banking, retail to automotive, cybersecurity to autonomous vehicles, synthetic data is making waves across various industries. By customizing synthetic data to mirror the traits and distributions of the target domain, we can design and test AI systems more successfully. This means we can create more accurate models, make more precise predictions, and deliver better results, no matter what industry we’re in.
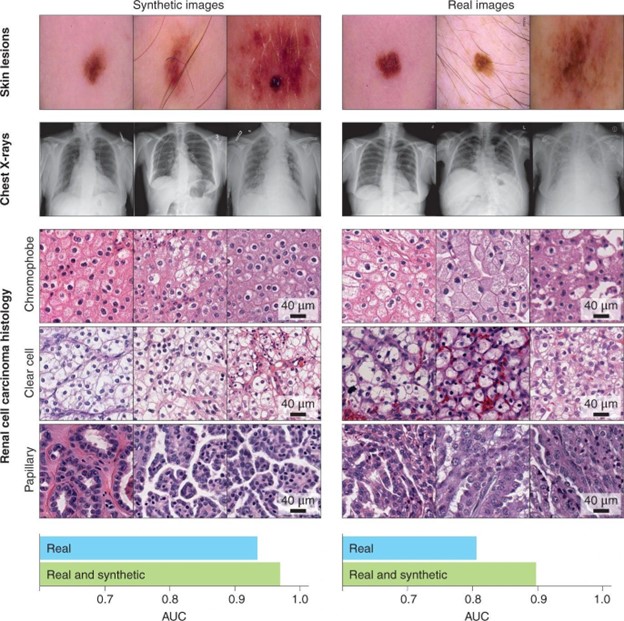
Top: synthetic and real images of skin lesions and of frontal chest X-rays. Middle: synthetic and real histology images of three subtypes of renal cell carcinoma. Bottom: areas under the receiver operating characteristic curve (AUC) for the classification performance of an independent dataset of the histology images by a deep-learning model trained with 10,000 real images of each subtype and by the same model trained with the real-image dataset augmented by 10,000 synthetic images of each subtype. (Source: https://www.nature.com/articles/s41551-021-00751-8/figures/1)
In healthcare, researchers have used synthetic data to predict patient mortality, enabling them to develop more effective treatment plans without compromising patient privacy. In finance, companies use synthetic data to test trading algorithms, allowing them to optimize their strategies and maximize their profits. In the automotive industry, companies like Waymo and Uber use synthetic data to train their self-driving algorithms, helping them to develop safer, more reliable autonomous vehicles. In the realm of cybersecurity, synthetic data is used to test the effectiveness of security systems, ensuring they can detect and respond to a wide range of cyber threats. And in retail, synthetic data is used to simulate customer behavior and test different business strategies, helping businesses to optimize their operations and boost their sales.
In conclusion, synthetic data is a powerful tool that can help businesses overcome the challenges of data collection and privacy, improve the quality and efficiency of their AI/ML models and data analytics processes, and enable effective data sharing and collaboration. As the synthetic data generation market continues to grow, we can expect to see even more innovative applications of this technology in the future.
The Advantages and Limitations of Synthetic Data
Synthetic data, a digital doppelgänger of real-world data, is a testament to our ability to create, control, and manipulate digital realities. But like any tool, it has its strengths and weaknesses, its pros and cons.

Image source: https://www.freepik.com/free-ai-image/man-glasses-holds-sphere-front-screen-that-says-future-technology_42883921.htm
The Upside: Advantages of Synthetic Data
A Solution to Data Collection Woes: Collecting real-world data can be a Herculean task, often requiring significant resources, time, and money. Synthetic data, on the other hand, can be generated quickly and in large quantities, tailored to specific needs. It is like having a personal data factory, churning out the data you need, when you need it. For instance, consider the automotive industry. Simulating car crashes using synthetic data is not only safer but also significantly cheaper than orchestrating real-world crash tests.
Speed, Volume, and Automatic Labeling: Synthetic data is like a well-oiled machine, capable of producing large volumes of data at a rapid pace. This is particularly beneficial for machine learning models, which often require vast amounts of data for training. Moreover, synthetic data comes with the added advantage of automatic labeling, which can significantly speed up the model development process and ensure labeling accuracy.
The Edge Case Conundrum: Real-world data often fails to capture edge cases, those rare scenarios that occur at extreme operating parameters. Synthetic data, however, can be tailored to simulate these edge cases, providing a more comprehensive dataset for building robust machine learning models.
Privacy: In an era where data privacy is paramount, synthetic data offers a solution. It can resemble real data in structure and statistics, but it doesn’t contain any personally identifiable information (PII), making it a suitable choice for industries like healthcare and finance where data privacy is a major concern.
Control Over Data: With synthetic data, you are the puppet master. You have complete control over every aspect of the data, from event frequency to item distribution. This level of control is particularly beneficial in machine learning, where you can manipulate factors like class separations, sampling size, and noise levels in the dataset.
The Flip Side: Challenges and Limitations of Synthetic Data

Image source: https://www.freepik.com/free-vector/people-analyzing-growth-charts_12643928.htm
Complexity: Real-world data is complex, often containing intricate relationships and patterns that can be difficult to reproduce artificially. Synthetic data, while useful, may not always capture this complexity accurately.
The Authentic Data Problem: Synthetic data is not a magic wand that can replace authentic data. Real, accurate data is still required to generate useful synthetic examples. This is particularly crucial in fields where the authenticity and accuracy of data are of utmost importance.
Quality Control: Generating synthetic data is not a set-it-and-forget-it process. It requires careful quality control to ensure that the synthetic data accurately reflects the characteristics of the original data. This can be a challenging and time-consuming process.
Privacy Paradox: While synthetic data is designed to protect privacy, there is a risk that it could inadvertently contain information that could identify individuals, particularly if the synthetic data is based on sensitive real-world data.
The Cost-Time Tradeoff: While synthetic data can be cheaper and faster to produce than collecting real-world data, generating high-quality synthetic data can still be costly and time-consuming, especially for complex datasets that require sophisticated algorithms and computational resources.
Expertise: Generating synthetic data is not a task for the faint-hearted. It requires a high level of expertise in data science and machine learning, which can be a barrier for organizations that lack these skills in-house.
Bias and Fairness: Synthetic data can either mitigate or exacerbate biases present in the original data. If the original data is biased, the synthetic data generated from it will also be biased. However, synthetic data can also be used to correct for biases in the original data by generating a more balanced dataset.
Potential for misuse: Like any tool, synthetic data can be misused. For example, it could be used to generate misleading results or support false claims. This risk can be mitigated by ensuring responsible use of synthetic data and validating results against real data.
Legal and Regulatory Frameworks
As the use of synthetic data increases, legal and regulatory frameworks are being developed to govern its use. These frameworks aim to ensure the responsible use of synthetic data and the protection of privacy and confidentiality.
It is important to be transparent about the use of synthetic data and to hold those who misuse it accountable. This includes being clear about when and how synthetic data is being used and ensuring that those who misuse synthetic data are held responsible.
In some cases, it may be necessary to obtain informed consent from individuals before using their data to generate synthetic data. This is particularly important in situations where the synthetic data could be used in a way that impacts the individuals whose data was used to generate it.
Synthetic data, like any tool, is not without its flaws. But its potential benefits make it a powerful asset in the world of data science and machine learning. As we continue to explore and refine this technology, we must also ensure that we navigate its challenges responsibly and ethically.
The Future of Synthetic Data

Image source: https://www.freepik.com/free-ai-image/abstract-futuristic-portrait-young-adult-cyborg-generated-by-ai_41594452.htm
- Market Growth: The global Synthetic Data Generation Market size is projected to reach USD 2.1 billion by 2028, at a Compound Annual Growth Rate (CAGR) of 45.7% during the forecast period from 2023 to 2028. This growth can be attributed to increasing concerns about data privacy and security, and the cost-effectiveness and time efficiency of generating synthetic data compared to collecting and labeling real-world data.
- Deep Learning Methods: Deep learning methods, such as variational autoencoders (VAEs) and generative adversarial networks (GANs), have shown considerable promise for producing synthetic data that is as realistic as possible. These techniques enable the development of more precise synthetic datasets by capturing complicated patterns and connections found in real data.
- Industry Applications: Many different industries, including healthcare, banking, retail, and autonomous driving, are finding uses for synthetic data generation. By customizing synthetic data to mirror the traits and distributions of the target domain, it is possible to design and test AI systems more successfully.
- Partnerships and Collaborations: Data providers and AI firms are collaborating and forming partnerships to address the rising need for high-quality synthetic data. These partnerships aim to provide more specialized and tailored synthetic data solutions by combining their skills in creating synthetic datasets and AI businesses’ subject expertise and understanding of specific industry demands.
- Standardization Efforts: There have been efforts made towards standardization in order to create benchmarks and ensure the quality of synthetic data-generating techniques. Organizations and academic communities have been focusing on establishing evaluation metrics, creating benchmark datasets, and exchanging best practices.
- Ethical Considerations: The ethical implications of creating synthetic data have drawn more attention. Concerns about biases, fairness, and potential exploitation of synthetic data must be addressed as the usage of synthetic data increases. Legal frameworks and regulations are being created to ensure responsible use and guard against unforeseen consequences.
Conclusion

Image source: https://www.freepik.com/free-ai-image/man-stands-front-brain-ball-dark-room_42191239.htm
Just as the dream architects in the movie Inception used the dreamer’s subconscious to create a synthetic reality, data scientists today are using synthetic data to construct digital realities that can be used to train AI models, test software, and conduct research in a variety of fields. The potential of synthetic data is immense, and as we have seen, it is already being used in a variety of innovative ways. However, it is important for organizations to use synthetic data responsibly, ensuring that it is used in a way that respects privacy, avoids bias, and produces reliable results.