

In the realm of the big screen, there’s a man who needs no introduction. A man of resourcefulness, a man of ingenuity, a man who could turn a paperclip into a key to conquer the most impossible of missions.
His name? Ethan Hunt.
He is the embodiment of the idea that necessity is the mother of invention, a beacon of hope in a world often too reliant on the conventional.

Source: Pexels
Now, imagine if Cruise’s Ethan Hunt was not a man, but a machine. A machine that could learn from scratch, without any prior knowledge or instruction, to solve complex problems. This is the essence of zero-shot learning, a concept in artificial intelligence that’s as fascinating as it is revolutionary. It’s like Ethan Hunt in digital form, a testament to the power of ingenuity and the limitless potential of learning.
Zero-shot learning is a leap forward in the field of AI, a step towards creating machines that can learn and adapt in ways we’ve only dreamed of. It’s about teaching machines to think outside the box, to approach problems with a fresh perspective, and to find solutions in the most unexpected places. It’s about creating a new kind of intelligence, one that’s as versatile and adaptable as the human mind.
Just as everyone’s favorite maverick agent uses his wits and creativity to save the day, zero-shot learning aims to equip machines with the ability to learn from the unknown. In this article, we will delve deeper into the capabilities of zero-shot learning, and in doing so, glimpse into a future where machines can learn, adapt, and innovate in ways we can hardly imagine.
Understanding Zero Shot Learning
Imagine Hunt, our resourceful hero, in a dimly lit room, surrounded by an array of objects that, to the untrained eye, seem unrelated and insignificant. But, with his keen eye and inventive mind, he sees potential. He sees a paperclip, not as a mere tool for holding papers together, but as a makeshift lock pick. He sees a rubber band, not as a simple office supply, but as a potential slingshot. This is the essence of zero-shot learning.

In the world of artificial intelligence, zero-shot learning is about teaching machines to make sense of the unknown, to find patterns in the chaos, to draw conclusions from seemingly unrelated data. Real-world examples of these concepts are abundant. For instance, face recognition systems often use one-shot learning, where the system can recognize a person’s face after seeing it only once. Zero-shot learning, on the other hand, is used in tasks like image captioning and natural language understanding where the model needs to generalize to classes not seen during training.
At the heart of zero-shot learning is the concept of semantic representation. This is the process of mapping input data, such as images or text, to a semantic space, such as attribute space or word vector space. The goal is to create a model that can understand the underlying meaning or context of the data, rather than just the raw data itself.
Consider an image of a cat. To a machine, this image is just a collection of pixels. But to a human, it’s much more. We see the cat’s fur, its eyes, its whiskers.

Source: Francesco Ungaro on Pexels
We understand that it’s a small, domesticated carnivorous mammal with soft fur, a short snout, and retractable claws. This is the kind of understanding that zero-shot learning aims to achieve.
In the training phase, a zero-shot model learns to associate input examples with their semantic representations. For instance, it might learn that images of cats are associated with certain attributes, like “small”, “furry”, and “four-legged”. This association is learned from known classes, which are classes that the model has seen during training.
But the real magic happens when the model encounters unknown classes, which are classes that it has not seen during training. Using the semantic representations it has learned, the model can make educated guesses about these unknown classes.

Source: Waldemar on Pexels
For example, if it encounters an image of a tiger, it might recognize that the tiger shares certain attributes with the cat, like being “furry” and “four-legged”, and thus classify it correctly, even though it has never seen a tiger before.
Broadly, zero-shot learning methods can be categorized as follows.
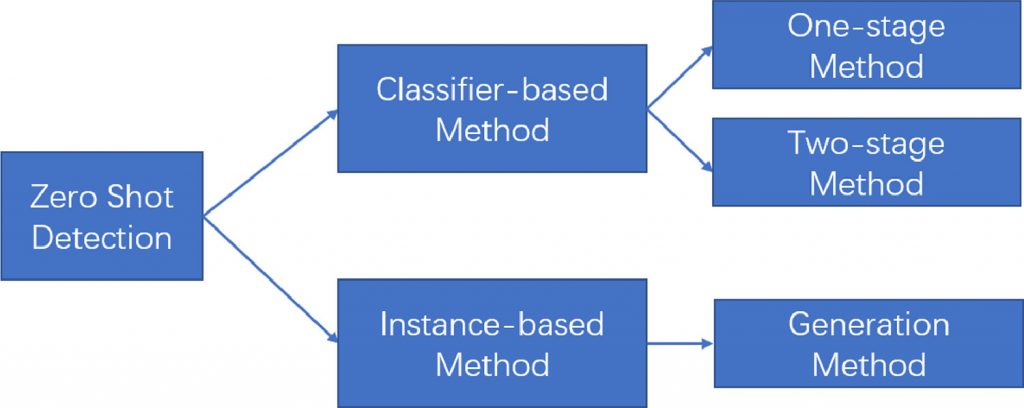
Source: Tan, C., Xu, X., & Shen, F. (2021). A Survey Of zero shot detection: Methods and applications. Cognitive Robotics, 1, 159–167. https://doi.org/10.1016/j.cogr.2021.08.001
- Classifier-based methods: Classifier-based zero-shot learning, on the other hand, constructs a classifier for each unseen class based on the seen classes. A classifier is a function that takes an input (like a picture) and assigns it to one of several categories (like ‘apple’, ‘banana’, or ‘orange’). In classifier-based zero-shot learning, the model uses the information it has learned from the seen classes to build a new classifier for the unseen classes.
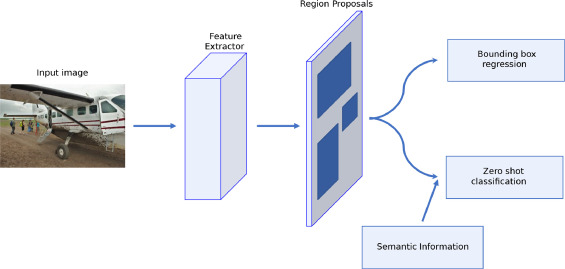
Two-stage detection-based zero-shot learning.
(Source: Tan et al., 2021)
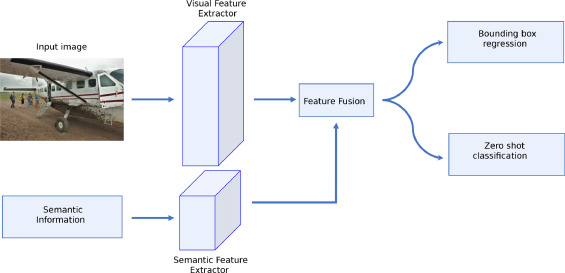
One-stage detection-based zero-shot learning
(Source: Tan et al., 2021)
- Instance-based methods: Instance-based zero-shot learning, on the other hand, is a method that focuses on comparing the individual instances of the unseen classes with the seen classes. In other words, it tries to match a new, unseen instance (for example, a picture of a rare bird species) with similar instances from the seen classes (pictures of common bird species).
Zero Shot Learning in LLMs
OpenAI’s GPT-3.5/4 and CLIP models are prime examples of large language models that utilize zero-shot learning. GPT-3.5/4, with its billions of machine learning parameters, is capable of tasks such as translation, question-answering, and even writing in a specific style without explicit training on these tasks. This is achieved through zero-shot learning, where the model can generalize its learning from the vast amount of data it was trained on to perform tasks it has not explicitly seen during training.
Similarly, OpenAI’s CLIP (Contrastive Language–Image Pretraining), is another example of a large language model that utilizes zero-shot learning. CLIP learns a joint embedding of images and text, allowing it to generalize to a wide range of tasks not seen during training. This means that CLIP can understand an image and its associated text in a way that previous models could not, making it a powerful tool for tasks such as image recognition and classification.
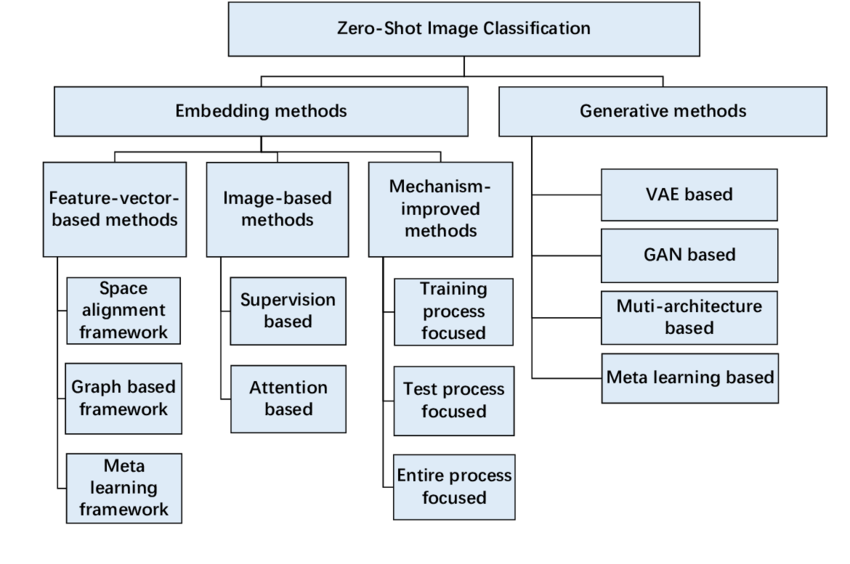
The taxonomy structural diagram for Zero-Shot image classification methods (Source: Yang et al., 2022)
The CLIP model is trained on a dataset of 400 million (image, text) pairs collected from the internet. The pre-training task is simple: predict which caption goes with which image. This task, though simple, is an efficient and scalable way to learn state-of-the-art image representations from scratch.
After pre-training, natural language is used to reference learned visual concepts or describe new ones, enabling zero-shot transfer of the model to downstream tasks. The model was benchmarked on over 30 different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification.
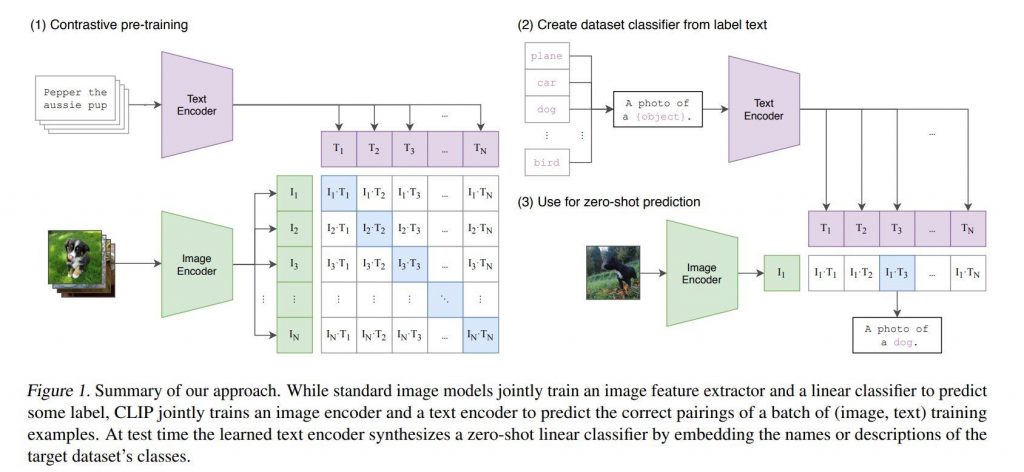
Source: arXiv:2103.00020
The results were impressive. The model transferred non-trivially to most tasks and was often competitive with a fully supervised baseline without the need for any dataset-specific training. For instance, it matched the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training examples it was trained on.
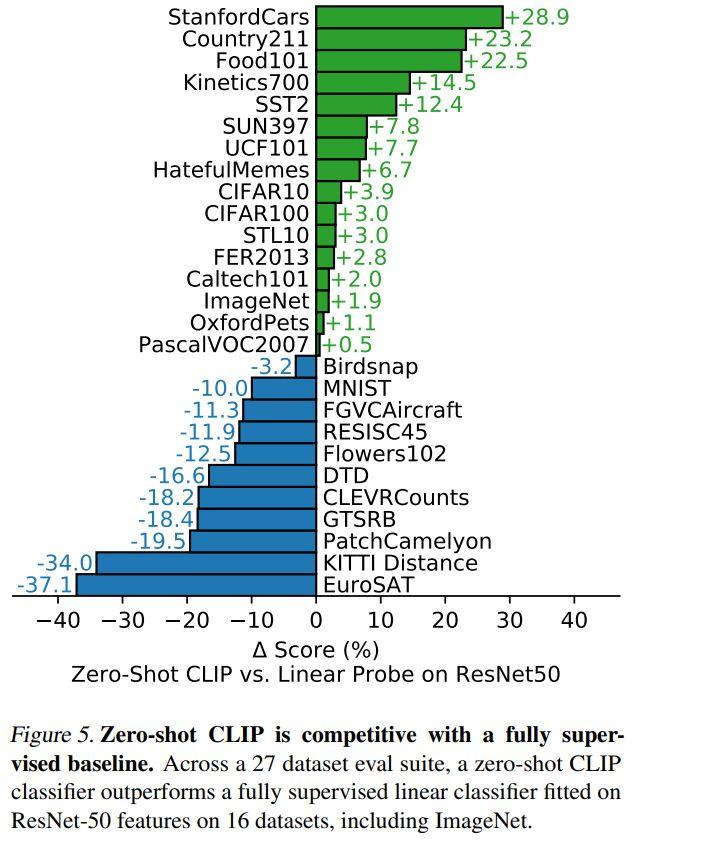
Source: arXiv:2103.00020
By learning directly from raw text about images, the model was able to leverage a much broader source of supervision, allowing it to generalize to a wide range of tasks not seen during training.
The success of the CLIP model is a testament to the potential of zero-shot learning in large language models. In essence, zero-shot learning in large language models is like giving Ethan a new set of tools and materials he’s never seen before. Despite the unfamiliarity, he’s able to understand and utilize them effectively because of his broad and versatile skill set.
Zero Shot Big Data & Analytics
Alright, let’s delve into the world of big data and analytics, where zero-shot learning is making waves. Every day, countless events unfold, each one generating a wealth of data. This data is like a vast, intricate tapestry, woven from countless threads of information. And just like a tapestry, it can be challenging to make sense of the whole picture when you’re up close, tangled in the individual threads unless you have zero-shot learning’s ability to generalize to new scenarios not seen during training.
Consider sentiment analysis, a task that involves determining the sentiment expressed in a piece of text. This is a classic example of a problem where zero-shot learning can shine. The model needs to understand the sentiment of text it has not seen during training.
In a typical scenario, a model would be trained on a large dataset of text annotated with sentiments (like positive, negative, or neutral). However, with zero-shot learning, the model can generalize to understand the sentiment of text it has not seen during training. For instance, it can understand that the sentence “I love this product!” expresses a positive sentiment, even if it has never seen that exact sentence before. This is because it has learned the semantic representation of words and phrases that generally express positive sentiment, such as “love” and “this product”.
Another fascinating example is demonstrated in the paper titled “Zero-Shot Learning for Code Education: Rubric Sampling with Deep Learning Inference” which presents a novel application of zero-shot learning in the field of code education. The authors propose a method to automatically generate grading rubrics for programming assignments, which can be a labor-intensive task for educators.
The method involves training a model on a dataset of programming assignments and their associated grading rubrics. The model learns to associate specific code features with certain rubric items. Once trained, the model can generate a rubric for a new programming assignment by identifying relevant code features in the assignment and associating them with appropriate rubric items. This is a zero-shot learning task because the model is generating rubrics for assignments it has not seen during training.
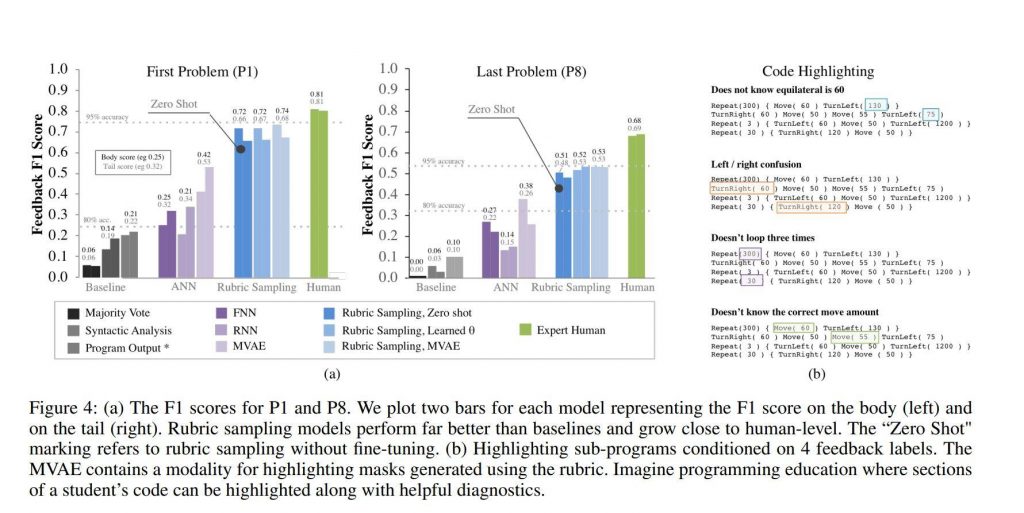
Source: arXiv:1809.01357v2
The authors evaluate their method on a dataset of programming assignments from an introductory computer science course and find that it can generate relevant rubric items for new assignments. This suggests that zero-shot learning could be a valuable tool in code education, helping educators to automate the process of grading and providing feedback on programming assignments.
Challenges, Applications, and Future
Zero-shot learning has the potential to revolutionize various fields by dealing with unseen data. However, like any burgeoning field, it faces challenges.
- Attribute Selection and Annotation: The selection of attributes is a critical aspect of zero-shot learning. The attributes should be discriminative enough to distinguish between different classes. However, the process of attribute selection and annotation is labor-intensive and requires domain knowledge. In the future, automatic attribute discovery and annotation could be a promising direction.
- Attribute Correlation: Attributes are not independent of each other, and there is often a correlation between them. For example, the attribute “has wings” is often associated with “can fly”. Current zero-shot learning methods often ignore these correlations, which could lead to sub-optimal performance. Future research could focus on modeling these attribute correlations.
- Semantic Embedding Space: The choice of semantic embedding space is crucial in zero-shot learning. Currently, attribute vectors and word vectors are the most used semantic spaces. However, these spaces may not be optimal for all tasks. Future research could explore other types of semantic spaces, such as description-based or hierarchy-based spaces.
- Generalized Zero-Shot Learning: In traditional zero-shot learning, the test classes are disjointed from the training classes. However, in many real-world scenarios, the test data may come from both seen and unseen classes. This scenario is known as generalized zero-shot learning.

Zero shot learning(ZSL) vs. Generalized zero shot learning (GZSL)
Source: arXiv:1707.00600v4Most current methods perform poorly in this setting. Future research could focus on improving the performance of zero-shot learning in this generalized setting.
- Cross-Domain and Cross-Modal Zero-Shot Learning: Zero-shot learning is not limited to single-modal or single-domain tasks. Cross-domain and cross-modal zero-shot learning, where the source and target domains or modalities are different, is a challenging and promising research direction.
- Evaluation Metrics: The evaluation of zero-shot learning methods is another challenge. Current evaluation metrics may not fully reflect the performance of zero-shot learning methods, especially in the generalized setting. Future research could focus on developing more appropriate evaluation metrics for zero-shot learning.
- Scalability: As the number of classes increases, the complexity of zero-shot learning also increases. Current methods may not scale well to a large number of classes. Future research could focus on developing scalable zero-shot learning methods.
- Robustness and Stability: Zero-shot learning methods should be robust to noise in the attribute annotations and stable under different parameter settings. However, current methods often lack robustness and stability. Future research could focus on improving the robustness and stability of zero-shot learning methods.
- Interpretability: Zero-shot learning methods should be interpretable, i.e., it should be clear how the method makes its predictions. However, current methods often lack interpretability. Future research could focus on developing interpretable zero-shot learning methods.
Applications of Zero Shot Learning
Zero-shot learning has been integrated into a myriad of applications.
- Image Recognition: Zero-shot learning can be used to recognize images of objects or scenes that the model has not seen during training. For instance, a model trained on images of dogs and cats might be able to recognize an image of a tiger by associating it with similar features found in the training data.
- Natural Language Processing (NLP): In NLP, zero-shot learning can be used to understand and generate text that the model has not been trained on. This can be particularly useful in tasks such as translation, sentiment analysis, and text generation. For example, a model trained on English text might be able to generate text in French, even if it has not been explicitly trained on French text.
- Medical Diagnosis: Zero-shot learning can be used in medical diagnosis to identify diseases or conditions that the model has not been trained on. For example, a model trained on images of different skin diseases might be able to identify a rare skin condition by associating it with similar features found in the training data.
- Object Detection: Zero-shot learning can be used to detect objects in images or video that the model has not been trained to recognize. For example, a model trained on images of cars and trucks might be able to detect a bicycle in an image, even if it has not been trained on images of bicycles.
- Computational Biology: Zero-shot learning can be used in computational biology to predict the properties of biological entities that have not been observed during training. For example, it can be used to predict the properties of a new strain of a virus based on its genetic sequence and auxiliary information about similar viruses.
Conclusion
We stand on the precipice of a new era in artificial intelligence, a future where AI models, like seasoned explorers, venture into the unknown, making sense of unseen data and delivering insights that drive innovation and progress.
From image classification and semantic segmentation to natural language processing and computational biology, the applications of zero-shot learning are as diverse as they are impactful. And as research progresses and technology evolves, we can expect to see even more innovative applications that harness the power of zero-shot learning to solve complex problems and deliver valuable insights.
It’s a testament to the power of AI, a demonstration of its potential to transform industries and revolutionize the way we live and work.