


The emergence of foundation models represents a seismic shift in the world of artificial intelligence. Foundation models are like digital polymaths, capable of mastering everything from language to vision to creativity.
Have you ever wanted to know what a refined, gentlemanly Shiba Inu might look like on a European vacation? Of course you have. Well, thanks to foundation models like DALL-E, now you can.

Introduction to Foundation models
In the summer of 2021, Stanford researchers published a 214-page study that defined foundation models as AI neural networks trained on massive amounts of raw data (usually with unsupervised learning) that can be adapted to a wide variety of tasks. Foundation models are designed to learn about the world and all of its complexities by processing massive amounts of data, such as text, images, and other forms of media. They are a toolkit for AI developers – they provide a starting point for creating new applications and solving complex problems, while still allowing for customization.
One simple example of a foundation model is a large language model (LLM) like ChatGPT. These models are trained on large amounts of text and can then generate human-like responses to prompts or questions. For example, you can ask a language model like ChatGPT to write a poem, and it will generate a unique poem for you based on its training data.
Since foundation models are capable of learning from unlabeled data sets with unsupervised learning, they can handle jobs from translating text to analyzing medical images with a little fine-tuning. These models are typically very large and complex and require significant computational resources to train and deploy.
To give you an idea of just how big an LLM like GPT-3 is, consider this: printing out the entire model would take up over 700,000 pages. That is equivalent to about 3,500 novels!
History and Evolution of Foundation Models
While the quest for developing generalized AI systems has been ongoing since the 1950s, the most significant breakthroughs in the field have been much more recent. One of the earliest and most influential foundation models was the ImageNet project launched in 2009. The project involved training a deep neural network on a massive dataset of labeled images. The resulting model, AlexNet, outperformed previous state-of-the-art computer vision systems by a wide margin.
In 2017, a team of Google scientists published a seminal paper on the Transformer architecture. This paper inspired several researchers to create BERT, GPT-2, and other LLMs that set new benchmarks for understanding and generating language. In 2020, OpenAI released GPT-3, another path-breaking transformer that was rapidly adopted by millions of people.
The popularization of self-supervised learning combined with a generous influx of funding from deep-pocketed corporations, governments, and other enterprises has allowed foundation models to reach unprecedented levels of sophistication and capability.
(Image source: OPEN AI)
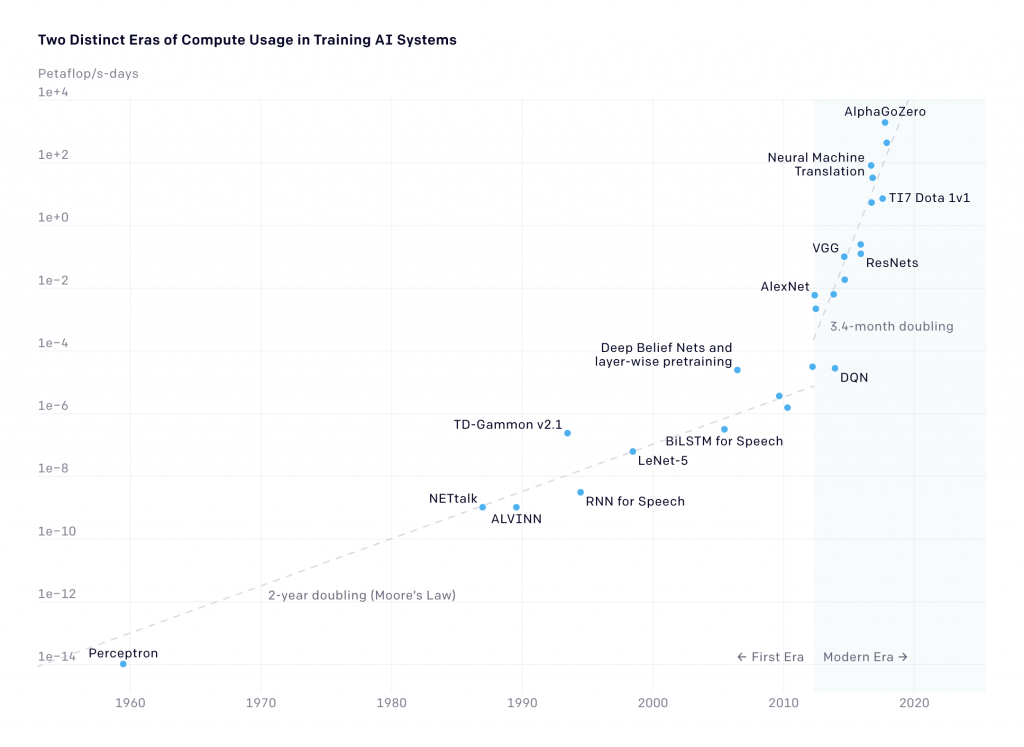
In the realm of machine learning, “bigger is better” is a tried and tested method for advancing the state-of-the-art with studies proving that model performance scales with the amount of computing. According to Open AI, the amount of computing required for the largest AI training runs doubles every 3.5 months, vastly outpacing Moore’s Law (2-year doubling period). To put this scaling over time into perspective, one of the earliest foundation models, BERT-Large was trained with 340 million parameters. In comparison, the largest foundation model today – the appropriately named Megatron Turing NLG 530B, is trained with a mind-boggling 530 billion parameters!
Types of Foundation Models
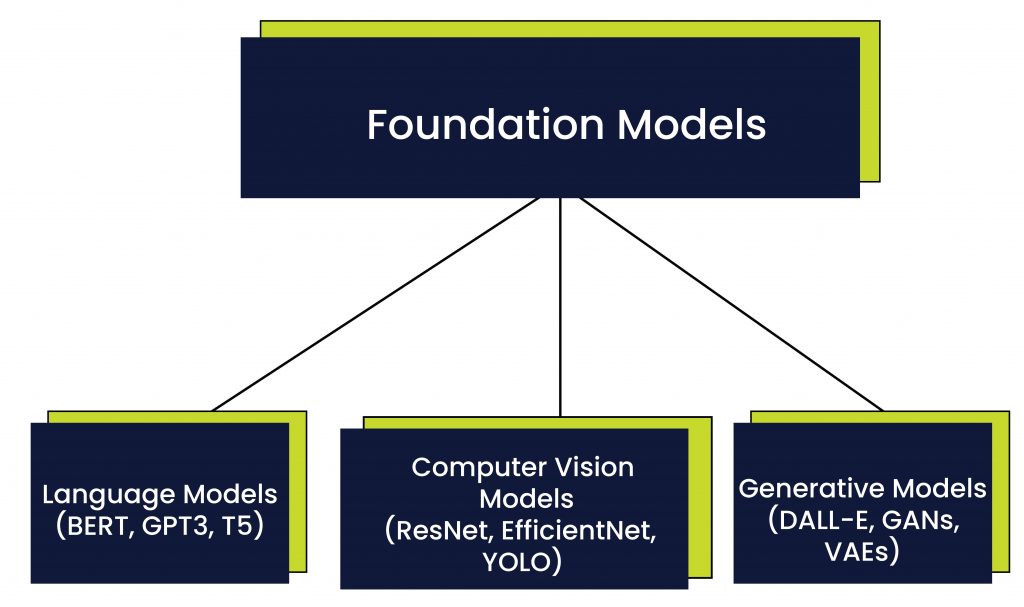
Foundation AI models can be broadly categorized into three types: language models, computer vision models, and generative models. Each of these types of models is designed to perform specific tasks and address specific challenges in the field of artificial intelligence.
- Language Models
Language models are the most well-known type of foundation AI models. These models are designed to process and understand natural language, allowing them to perform tasks like language translation, question answering, and text generation. Examples of popular language models include BERT, GPT-3, and T5.
| BERT (Bidirectional Encoder Representations from Transformers) developed by Google, is a pre-trained language model that is capable of understanding the nuances of natural language text. According to Google, BERT has outperformed previous language models based on recurrent neural networks (RNN) on a variety of natural language processing tasks, including question-answering, translation, sentiment analysis, and predictive text.
GPT-3, developed by OpenAI, is a much larger language model that has been trained on an incredibly large dataset. With 175 billion parameters, GPT-3 can generate text that is indistinguishable from that written by a human. This model has been used in a variety of applications, including chatbots and virtual assistants. T5 (Text-to-Text Transfer Transformer), is a more recent language model developed by Google that takes a different approach to natural language processing. Rather than being fine-tuned for specific tasks like BERT, T5 is a general-purpose language model that is trained to perform a wide range of tasks, including text classification, question answering, and summarization, among others. T5 uses a unified text-to-text format, which allows it to be easily adapted to a wide range of natural language processing tasks. |
- Computer Vision Models
Computer vision models are designed to process and analyze visual information, allowing them to perform tasks such as image classification, object detection, and image segmentation. Examples of popular computer vision models include ResNet, EfficientNet, and YOLO.
| ResNet, developed by Microsoft, is a deep neural network that is capable of classifying images with exceedingly high accuracy. This model has been used in a variety of applications, including image recognition for self-driving cars.
EfficientNet, developed by Google, is another computer vision model that has achieved state-of-the-art results on a variety of image classification tasks. This model is notable for its efficiency, requiring significantly fewer parameters than other leading computer vision models. YOLO (You Only Look Once), is a real-time object detection system that is capable of detecting objects in an image with very high accuracy. This model has been used in a variety of applications, including self-driving cars and security systems. |
- Generative Models
Generative models are designed to generate new data that is like existing data. These models can generate images, text, and even videos. Examples of popular generative models include DALL-E, GANs, and VAEs.
| DALL-E, developed by OpenAI, is a generative model that is capable of creating images from natural language prompts. This model has generated significant interest in the art community, as it is capable of generating images that are highly realistic and imaginative.
GANs (Generative Adversarial Networks), developed by Ian Goodfellow, are a type of generative model that is capable of generating new data by pitting two neural networks against each other. Google’s BigGAN is an example of this type of model, having been trained on a gigantic image dataset, making it capable of creating generative art with incredible detail and realism. BigGAN has been widely used in advertising, marketing, and even for generating virtual video game environments. VAEs (Variational Autoencoders) are a type of generative model that is capable of generating new data by learning the underlying structure of a dataset. These models have been used for applications like dimensionality reduction and anomaly detection. |
Foundational Models Are Not Omnipotent
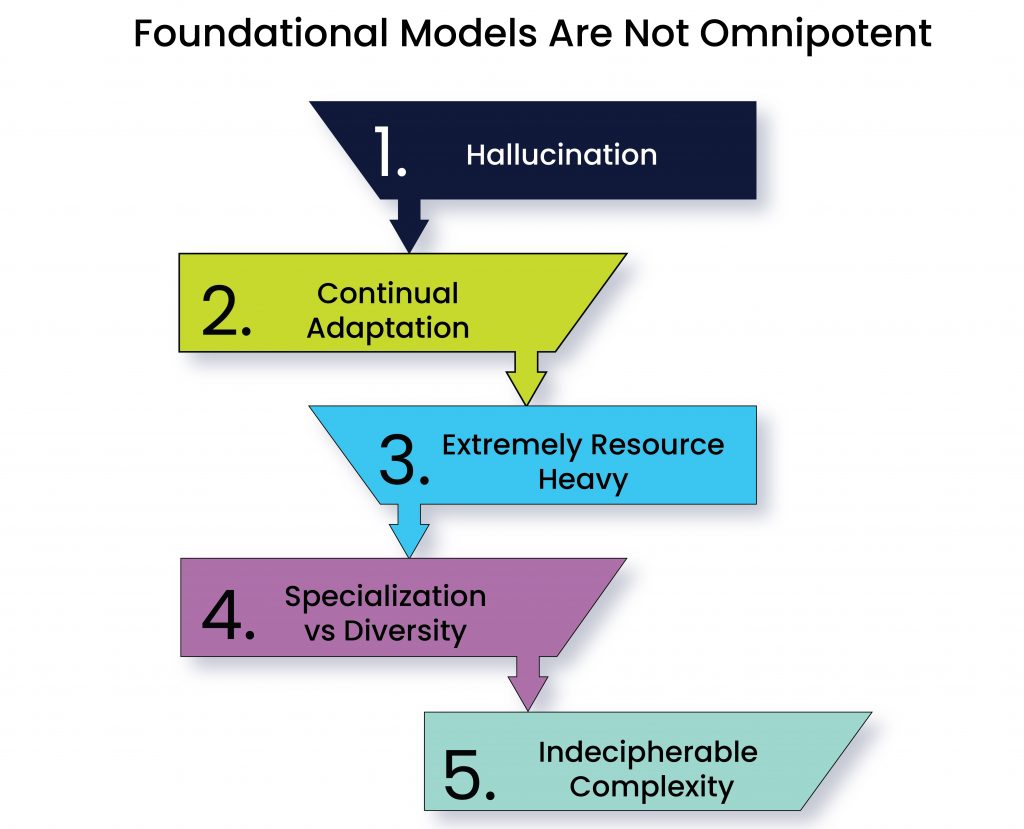
While foundation models have been rightly hailed for their groundbreaking capabilities in several applications, they are not without their limitations. Let us delve into some of the biggest ones.
- Hallucination
One of the most significant limitations of foundation models is their tendency to fabricate answers, also known as hallucination. This is especially true for language models, which have been known to generate responses that are technically correct but not true or relevant to the question. For instance, a language model might generate an answer to a question that is factually correct, but it may not be a useful or meaningful response in the context of the question.
- Continual Adaptation
Foundation models are typically trained on large datasets at a specific point in time, but the data they are trained on may quickly become outdated. As a result, the model’s performance may degrade over time if it is not continually fine-tuned with new data. This temporal shifting issue is especially problematic for real-world applications where the data is constantly changing.
- Extremely resource heavy
Foundation models also require massive amounts of data and computing for both training and evaluation. This means that developers need to have access to large, high-quality datasets and powerful computing resources to train and fine-tune these models effectively. Additionally, human evaluation is necessary for fine-tuning, which can be time-consuming and expensive.
- Specialization vs Diversity
Foundation models trained in specialized domains may struggle to generalize to new domains outside of their training data. On the other hand, models trained in a diverse range of domains may not perform as well in specific areas. Finding the right balance between specialization and diversity is an ongoing challenge for researchers and developers.
- Indecipherable complexity
Despite the immense power of foundation models, there is still a lack of understanding of how these models work. Researchers and developers often struggle to understand what a model can do, why it exhibits certain behaviors, and how it reaches specific conclusions. This lack of understanding makes it difficult to troubleshoot issues or make improvements to the models. The challenge is to find ways to adapt the model to new situations without losing the knowledge gained from previous training.
The Potential of Foundation Models
Factories and warehouses are already leveraging foundation models to simulate digital twins, which enables them to identify more efficient ways of working. These realistic simulations provide a safe space for experimenting with new ideas without any real-world repercussions, making them a valuable tool for refining industrial processes.
But, the applications of foundation models go beyond just language processing and simulation. They can aid in the training of autonomous vehicles and robots that are designed to assist humans on factory floors and logistics centers. Additionally, foundation models can be used to create realistic environments that autonomous vehicles can train in, enabling them to learn how to navigate through complex and challenging conditions in a safe and controlled environment. In the world of healthcare, they are being used to develop predictive models for diagnosis and drug discovery. They are also being utilized in various scientific disciplines such as physics and chemistry to power new discoveries and breakthroughs.
Looking Ahead
As we gaze into the crystal ball of the future of AI systems, it is becoming increasingly clear that foundation models will play a significant role. As a result, it is imperative that we as a community band together to develop more robust principles for foundation models and guidance for their responsible development and deployment. One approach is to filter both the prompts and outputs to prevent potential biases and harmful content. We should also recalibrate models in real-time to ensure they remain effective and trustworthy. It is also critical to scrutinize and scrub large datasets to ensure they do not reinforce harmful stereotypes or discriminatory practices. With a responsible and collaborative approach to foundation models, we can build a safer, more beneficial future powered by AI.
I wanted to take a moment to appreciate the helpfulness of this post. It clarified several doubts I had and presented the information in an organized manner. Great work!