

Picture yourself as a culinary maestro. You have dedicated countless hours in the kitchen, mastering the nuances of French cuisine, perfecting the art of sourdough, and orchestrating symphonies of flavor in a well-risen chocolate soufflé. Each culinary expedition has bestowed upon you a wealth of knowledge—harmonizing tastes, kneading the dough with finesse, and deftly tempering chocolate.
Now, when you have to whip out a new novel recipe, you don’t start from scratch. Instead, you deftly deploy the expertise and acumen amassed from your experience to whip up a delightful new creation. This, in essence, is the concept of transfer learning in the realm of artificial intelligence (AI).

Source: Pexels
In the vast and complex kitchen of AI, transfer learning has emerged as a powerful tool, a master chef in its own right. It is a machine learning method where a pre-trained model, which has learned a certain task, is reused as a starting point for a related task. It’s like using your knowledge of baking bread to make pizza dough. The underlying principles are the same, even if the recipe has changed.
The importance of transfer learning in AI cannot be overstated. It addresses key challenges in the field, such as data scarcity and the need for computational efficiency, and opens up new possibilities for the development and application of AI models.
In this article, we will embark on a journey to explore the fascinating world of transfer learning, its role in AI, and its potential to shape the future of this field. So, put on your apron, and let’s get cooking!
Understanding Transfer Learning
Just as a master chef draws on a wealth of culinary experiences to create new dishes, transfer learning empowers an AI model to apply knowledge gained from one task to a different, yet related, challenge. But how does this translate into practice?

Intuitive examples about transfer learning (Source: https://arxiv.org/pdf/1911.02685.pdf)
Let us reimagine the process of implementing transfer learning in the bustling kitchen of a renowned restaurant. The head chef, akin to a pre-trained model, is the mastermind behind the culinary creations. He has spent years honing his craft, learning the nuances of flavors, and understanding how ingredients interact. This is the pre-training phase, where the model acquires a broad base of knowledge from a large dataset.
So, when the time comes to add a new dish to the menu. The chef doesn’t start from scratch. Instead, he draws upon his vast experience, tweaking and adjusting recipes he already knows to create something new. This is the fine-tuning phase, where the model applies its general knowledge to a specific task. In the context of machine learning, this involves adjusting the weights of the pre-trained model using your own data, allowing the model to adapt to the specifics of your problem while still retaining the existing knowledge.
Finally, when the dish is served to the customers. Their feedback, whether it is praise or criticism, helps the chef refine the dish further. This is akin to evaluating the fine-tuned model on a test set to see how well it performs on unseen data. Their feedback will tell the chef, or in our case, the data scientist, how well the model has done in adapting its base knowledge to create a new, effective solution.
In this culinary concoction, each phase plays a crucial role. The chef’s broad culinary knowledge, his ability to adapt that knowledge to a specific dish, and the feedback from the customers all work together to create a dish that delights the palate. Similarly, in transfer learning, the selection of a pre-trained model, the fine-tuning of your own data, and the evaluation of a test set work together to create a model that effectively solves your specific problem.
Categories of Transfer Learning
Within the realm of transfer learning, we encounter several categorizations as illustrated in the image below, but for the purposes of this discussion, let us stick to the most widely used ones: inductive, transductive, and unsupervised transfer learning.
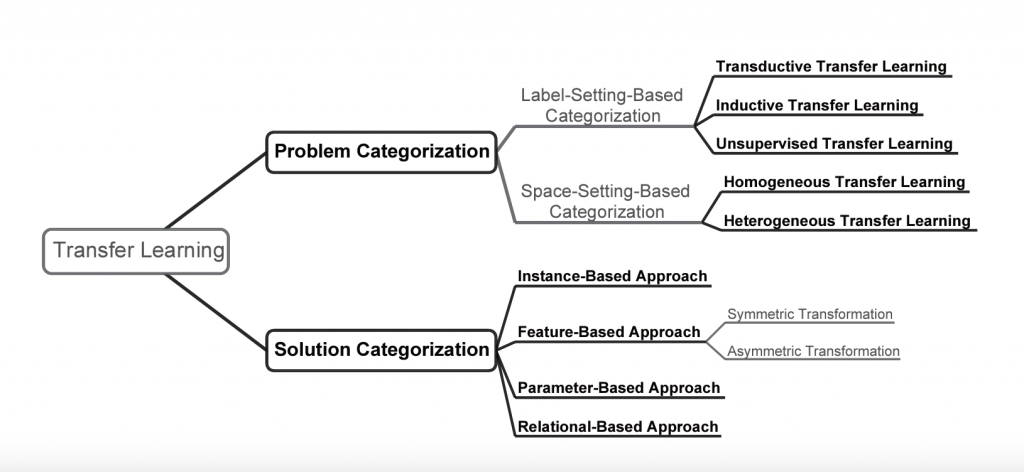
The categorizations of transfer learning (Source: https://arxiv.org/pdf/1911.02685.pdf)
- Inductive Transfer Learning: This form of transfer learning stands as the most prevalent. Here, the source and target tasks differ, but they share the same input space.
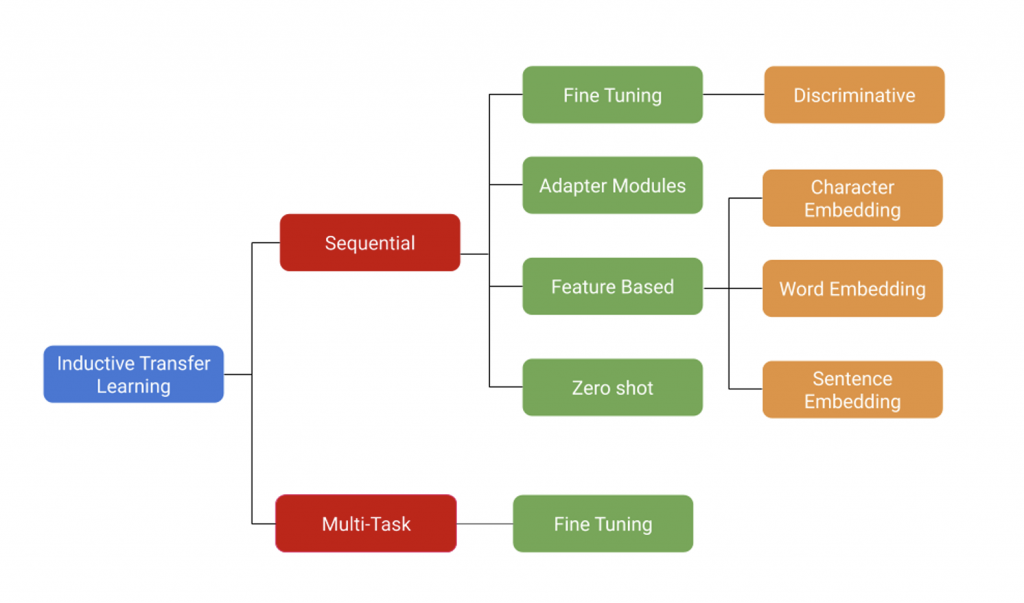
Inductive Transfer Learning (Source: https://arxiv.org/pdf/2007.04239.pdf)
- Transductive Transfer Learning: In this scenario, the source and target tasks remain the same, but the domains vary. This approach is typically employed when ample labeled data exists in one domain, and we seek to apply the model to a distinct domain. For instance, if we possess a model trained to recognize emotions in English text, we may desire to apply it to French text.
- Unsupervised Transfer Learning: This less common form of transfer learning arises when both the source and target tasks involve clustering. The objective here is to leverage the structural knowledge acquired from the source task to assist with the target task. Consider a scenario where we have clustered articles into various topics—employing the same structure can prove useful when clustering tweets.
In all these cases, the underlying principle remains consistent: leveraging knowledge gained from one task (the source) to enhance performance on a distinct yet related task (the target). This approach is particularly valuable when ample labeled data is available for the source task while the target task faces scarcity. By embracing the power of transfer learning, we enable AI to navigate the complexities of knowledge acquisition, drawing upon its diverse repertoire to achieve extraordinary results.
The Vital Role of Transfer Learning in AI
Transfer learning assumes a pivotal position in the realm of AI, revolutionizing the development and optimization of AI models.
Its contributions can be categorized into three fundamental areas: optimizing AI model efficiency, surmounting data scarcity, and enhancing model generalization.
Optimizing AI Model Efficiency
A paramount advantage of transfer learning lies in its capacity to optimize AI model efficiency. In traditional machine learning approaches, models are painstakingly trained from scratch, demanding substantial computational resources and time. However, transfer learning offers a respite by harnessing pre-existing models that have been trained on extensive datasets. These pre-trained models have already acquired invaluable features and patterns, which can be seamlessly transferred to a novel yet related task, effectively reducing the need for arduous computations.
For instance, in the field of computer vision, models pre-trained on vast datasets, such as ImageNet, serve as an invaluable starting point. When applied to new tasks, like medical image analysis, these models adeptly leverage their acquired knowledge, dramatically curtailing training time and computational demands.
A study titled “CNN Features off-the-shelf: an Astounding Baseline for Recognition”, demonstrates the effectiveness of this approach, showing that features from a deep convolutional network trained on ImageNet can serve as a powerful generic feature extractor for a variety of tasks.
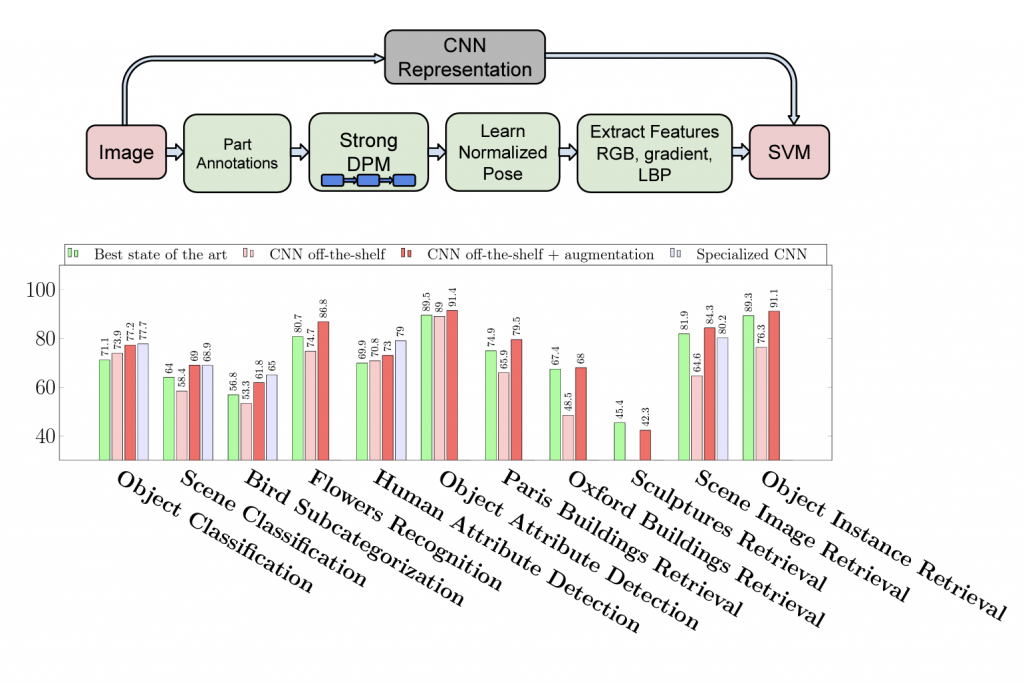
CNN representation replaces pipelines of state of art methods and achieve better results. e.g. DPD [50]. bottom) Augmented CNN representation with linear SVM consistently outperforms state. on multiple tasks. Specialized CNN refers to other works which specifically designed the CNN for their task (Source:https://arxiv.org/pdf/1403.6382.pdf)
Data scarcity poses a persistent challenge in AI, particularly in specialized domains where amassing ample labeled data proves difficult and costly. Here, transfer learning emerges as a potent solution by enabling the seamless transfer of knowledge from tasks blessed with abundant data to those grappling with scarcity.
In the realm of natural language processing (NLP), models pre-trained on vast text corpora, including renowned sources like Wikipedia, can be meticulously fine-tuned for specific tasks such as sentiment analysis or named entity recognition, even when the volume of labeled data available for these tasks is limited. A paper by Howard and Ruder, titled “Universal Language Model Fine-tuning for Text Classification”, provides a compelling example of this. The authors demonstrate that a language model pre-trained on a large corpus can be fine-tuned and achieve state-of-the-art results on various text classification tasks, even with minimal task-specific data.
Enhancing Model Generalization
Another notable contribution of transfer learning lies in enhancing the generalization abilities of AI models. Generalization refers to a model’s aptitude to perform well on unseen data. Traditional machine learning methods often stumble when confronted with disparities between training and testing data distributions. However, transfer learning mitigates this challenge.
A study titled “How transferable are features in deep neural networks?”, provides insight into this aspect of transfer learning. The authors experimentally quantify the generality versus specificity of neurons in each layer of a deep convolutional neural network. They found that transferability is negatively affected by the specialization of higher-layer neurons to their original task at the expense of performance on the target task. However, they also found that initializing a network with transferred features from almost any number of layers can produce a boost to the generalization that lingers even after fine-tuning the target dataset.
In summary, transfer learning plays a vital role in AI, optimizing model efficiency, surmounting data scarcity, and bolstering model generalization. Its ability to harness pre-existing knowledge positions it as a powerful tool for cultivating robust and efficient AI models.
Transfer Learning and Large Language Models
Transfer learning plays a pivotal role in training large language models (LLMs) like GPT-3.5 and GPT-4. The fundamental idea behind transfer learning is to leverage knowledge gained while solving one problem and applying it to a different but related problem. In the context of LLMs, this involves pre-training a model on a large corpus of text and then fine-tuning it on a specific task. This approach is typically task-agnostic in architecture, but it still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples.
One of the significant advantages of transfer learning is that it enables LLMs to generalize knowledge across different tasks. This is akin to a chef who, after mastering the art of cooking various dishes, can easily adapt to preparing a new recipe by applying the skills and techniques learned from previous experiences. Similarly, LLMs can leverage the knowledge gained from pre-training to perform well on a variety of tasks.
A real-world example of how LLMs leverage transfer learning is the GPT-3.5 model developed by OpenAI. GPT-3.5 is an autoregressive language model with 175 billion parameters, making it 10x larger than any previous non-sparse language model. Despite its size, GPT-3.5 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. This approach allows GPT-3.5 to achieve strong performance on many NLP tasks, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation.
However, it’s important to note that while transfer learning greatly improves task-agnostic, few-shot performance, there are still some datasets where GPT-3.5’s few-shot learning struggles.
Transfer Learning in Analytics
Transfer learning is a powerful tool in the realm of predictive analytics. It allows models to leverage knowledge gained from one task and apply it to a different, but related task. This ability to transfer knowledge can significantly improve the efficiency and performance of predictive models, especially when dealing with large and complex datasets.
In the context of customer segmentation and behavior prediction, transfer learning can be particularly useful. For instance, a model trained to predict customer behavior in one market can transfer its learned patterns to predict behavior in a different market. This can be especially beneficial when the new market has limited data available. By leveraging the knowledge from the original market, the model can make accurate predictions in the new market, even with less data.
A real-world example of transfer learning in analytics can be found in the work of Ritchie Ng and his team at the National University of Singapore. They developed a GPU-based implementation for rapid large-scale rationalizing of time series data, which is a common task in predictive analytics. Their method called GPU Fractional Differencing (GFD), leverages transfer learning to achieve stationarity while maintaining the maximum amount of memory compared to traditional methods.
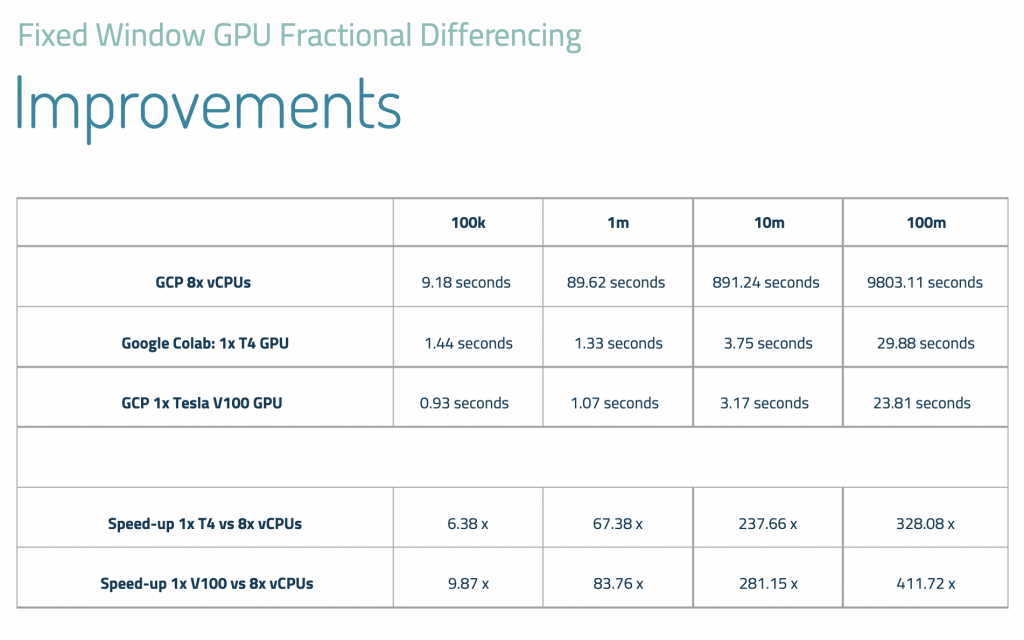
Source: https://www.researchgate.net/publication/335159299_GFD_GPU_Fractional_Differencing_for_Rapid_Large-scale_Stationarizing_of_Time_Series_Data_while_Minimizing_Memory_Loss
This approach allows for more efficient and effective predictive modeling in various applications, including customer behavior prediction.
In the next section, we will explore some more real-world applications of transfer learning across different domains of artificial intelligence.
Applications of Transfer Learning in AI
Healthcare and Bioinformatics: Alzheimer’s Disease Classification Based on Genome-Wide Data

Source: Freepik
A study conducted by Abbas Saad Alatrany and his team demonstrated the use of transfer learning in bioinformatics, specifically in the classification of Alzheimer’s Disease. The research utilized deep transfer learning with varying experimental analysis for reliable classification of Alzheimer’s Disease. The convolutional neural networks (CNN) were initially trained over the genome-wide association studies (GWAS) dataset requested from the Alzheimer’s Disease Neuroimaging Initiative. The team then employed deep transfer learning for further training of the CNN over a different Alzheimer’s Disease GWAS dataset, to extract the final set of features. These features were then fed into a Support Vector Machine for the classification of Alzheimer’s Disease. The study achieved an accuracy of 89%, which is a significant improvement when benchmarked with existing related works.
Computer Vision: Image Recognition

Source: Freepik
Transfer learning has revolutionized the field of computer vision, particularly in image recognition tasks. Pre-trained models trained on large datasets like ImageNet are often used as a starting point for image recognition tasks. For example, a study used a technique called Group Normalization (GN) as an alternative to Batch Normalization (BN) in training larger models for computer vision tasks including detection, segmentation, and video. The GN technique, which divides the channels into groups and computes within each group the mean and variance for normalization, was found to outperform its BN-based counterparts for object detection and segmentation in COCO, and for video classification in Kinetics.
Natural Language Processing: Sentiment Analysis

Source: Freepik
In Natural Language Processing (NLP), transfer learning has been used in sentiment analysis, which involves determining the sentiment expressed in a piece of text. Pre-trained models like BERT, which is trained on a large corpus of text from the internet, can be fine-tuned for sentiment analysis tasks, significantly reducing the amount of labeled data required.
Autonomous Vehicles: Object Detection
Source: Freepik
In the realm of autonomous vehicles, transfer learning is used in object detection, which is crucial for the safe operation of these vehicles. Pre-trained models trained on large datasets can be fine-tuned to detect objects in the specific context of autonomous driving.
Challenges and Limitations of Transfer Learning
Transfer learning, while powerful, is not without its challenges and limitations.
One of the primary challenges in implementing transfer learning is the issue of negative transfer. This occurs when the knowledge transferred from the source task to the target task is not beneficial but instead hinders the learning process. This typically happens when the source and target tasks are not sufficiently related. For instance, using a model trained on images of cars to identify types of flowers might not yield the best results, as the features learned from the car images may not be relevant to the flower images.
Another challenge is the risk of overfitting, especially when the target task has a small amount of data. If the pre-trained model is complex and the target task data is sparse, the model may overfit to the target task, leading to poor generalization performance.
Transfer learning also faces limitations in terms of the depth of the transferred layers. According to a study, the transferability of features decreases as the distance between the base task and target task increases. This means that lower layers, which capture more generic features, are more transferable than higher layers, which capture more specific features. Therefore, the choice of which layers to transfer and which to fine-tune is crucial in transfer learning.
By understanding these limitations, we can make more informed decisions when implementing transfer learning and improve the performance of our models.
The Future of Transfer Learning
The future of transfer learning involves multiple models, each trained on different data sets, working together to solve complex problems.
Recent research in transfer learning is pushing the boundaries of what is possible. For instance, a study titled “Transfer Learning with Dynamic Adversarial Adaptation Network” explores the use of adversarial networks to improve the transfer of knowledge between different domains. Another study, “Transfer Learning with Supervised Learning for Audio Classification”, investigates the use of transfer learning in audio classification tasks.
In the realm of natural language processing, the “Domain Generalization via Universal Non-volume Preserving Models” research proposes a novel approach to transfer learning that allows a model to generalize across multiple domains. Meanwhile, in the field of image processing, the “Semi-Supervised Transfer Learning for Image Rain Removal” study uses transfer learning to improve the performance of image rain removal tasks.
These advancements hint at a future where transfer learning is not just a tool for improving model performance, but a fundamental part of how we approach machine learning. As we continue to explore the vast potential of AI, tools like Scribble Data’s Enrich can help streamline the process of preparing data for machine learning models, allowing us to focus on what truly matters – creating an AI system that can learn, adapt, and innovate, just like our chef in the kitchen.