


Navigating through the labyrinthine streets of ancient Rome without a map or GPS, you would quickly realize how every landmark, road, and destination forms part of a larger, intricate whole. A wrong turn at the Pantheon could lead you away from the Colosseum,or a shortcut through Piazza Navona could help you stumble upon the grandeur of St. Peter’s Basilica sooner. In this context, you would appreciate how every piece of the city connects and relates to the others.
Similar complexities arise when dealing with human language in the realm of artificial intelligence, particularly within large language models (LLMs). Words, much like the streets of Rome, are interconnected, layered, and complex. The question then arises – how does an AI find its way through the dense and intricate linguistic terrain to understand and generate human-like text?

Our ‘map’ for this journey is a powerful technique known as “word vectorization”. This method positions words and phrases in a multi-dimensional space where the ‘distances’ and ‘directions’ between them encapsulate their meanings and relationships. This structured view of language enables LLMs to comprehend, contextualize, and generate text that is coherent, and sometimes, indistinguishably human-like.
In this article, we will deep dive into the world of word vectorization. We will uncover its significance, its role in powering AI and LLMs, and its enduring impact on the evolution of natural language understanding and generation.
Understanding word vectorization
Word vectorization is a powerful technique in natural language processing (NLP) that maps words or phrases from a vocabulary to a corresponding vector of real numbers. This ‘vectorization’ captures the semantic properties of the words, preserving the linguistic context in a mathematical format that can be processed by AI models.
To appreciate the power of this approach, consider the phrase “dog is to a puppy as a cat is to a kitten”. The semantic relationship between “dog” and “puppy” is akin to that between“cat” and “kitten“. Word vectorization captures these relationships by positioning the words in such a way that the vector difference between “dog” and “puppy” is like that between “cat” and “kitten”. The vector operations align with the semantic operations.
But why do we need to reduce words to vectors? It’s simple:machines understand numbers, not words. Computers are masters of numerical calculations but lack the natural capacity to understand human language. Word vectorization provides a bridge between the qualitative world of language and the quantitative world of machines. It allows us to represent words and their respective meanings in a format that AI can comprehend.
So, just like the detailed map of Rome that helps you navigate its streets, word vectorization allows AI to navigate the intricate world of human language. It’s like GPS for AI, providing the needed guidance to understand, interpret, and generate human-like text.
The mechanics of word vectorization
With an understanding of what word vectorization is, let’s delve into the heart of the matter: how do we convert words into vectors? Much like the grid of streets and landmarks helps you traverse the cityscape, word vectorization transforms words into numeric vectors, each serving as a distinct location in a multi-dimensional space, also known as vector space. Each word is a unique point in this space, and its location, relative to other words, encodes its meaning.
Consider the words ‘king’, ‘queen’, ‘man’, and ‘woman’. In a well-constructed vector space, the word ‘king’ is positioned as close to ‘queen’ as ‘man’ is to ‘woman’, capturing the relationship of royalty and gender in their respective contexts. The vector from ‘king’ to ‘queen’ should be like that from ‘man’ to ‘woman’. It is as if each word is a city, and the semantic relationships between words are the roads that connect them.
This translation of words into vectors is achieved using various mathematical models that learn these relationships from large amounts of text data. Let us briefly examine a few:
- One-hot Encoding: Think of one-hot encoding as the beginner’s method for word vectorization. It involves creating a vector that is as long as the vocabulary of the document or corpus, then marking the position of the word with a ‘1’ and leaving all other positions as ‘0’. For example, for the sentence ‘The cat sat on the mat,’ if ‘cat’ is the second word in our vocabulary, its one-hot encoded vector would look like [0, 1, 0, 0, 0, 0].
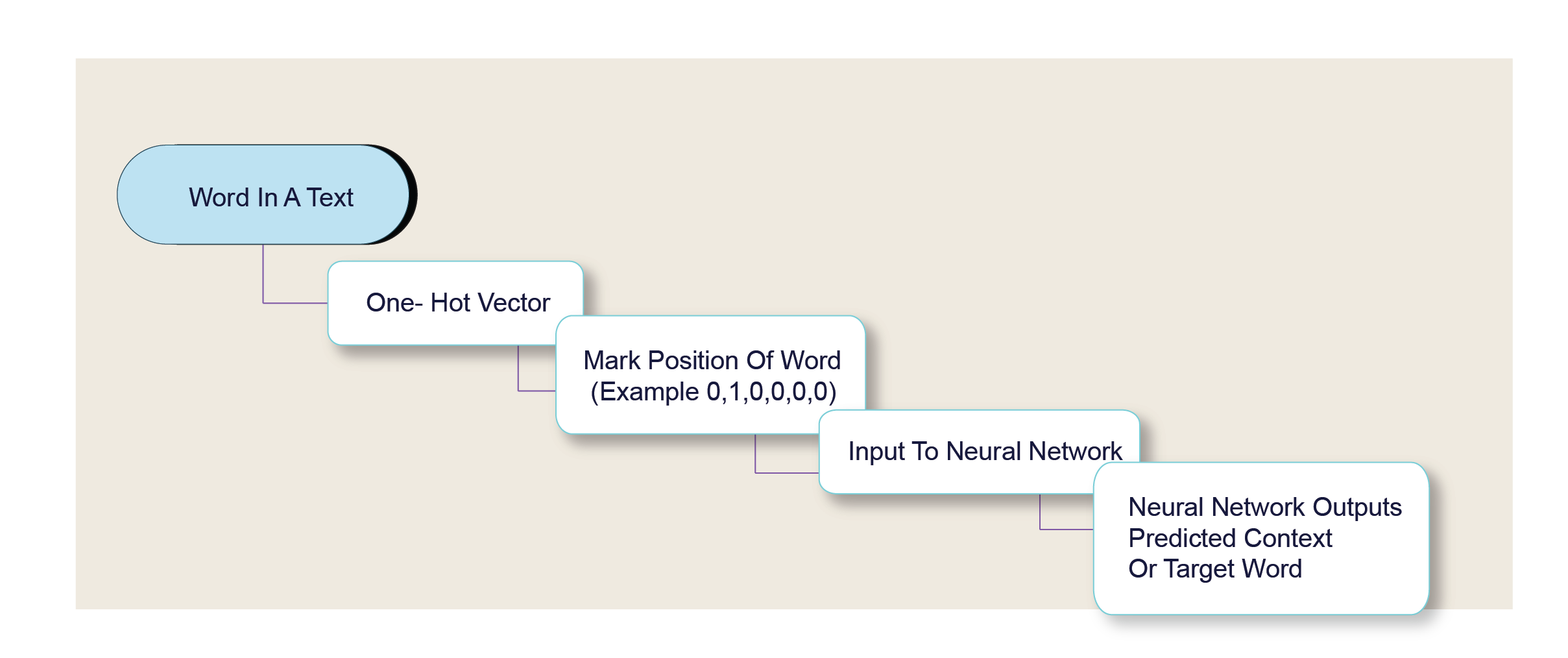
Although this method is simple and straightforward, it’s not efficient for large vocabularies and fails to capture the semantic relationships between words.
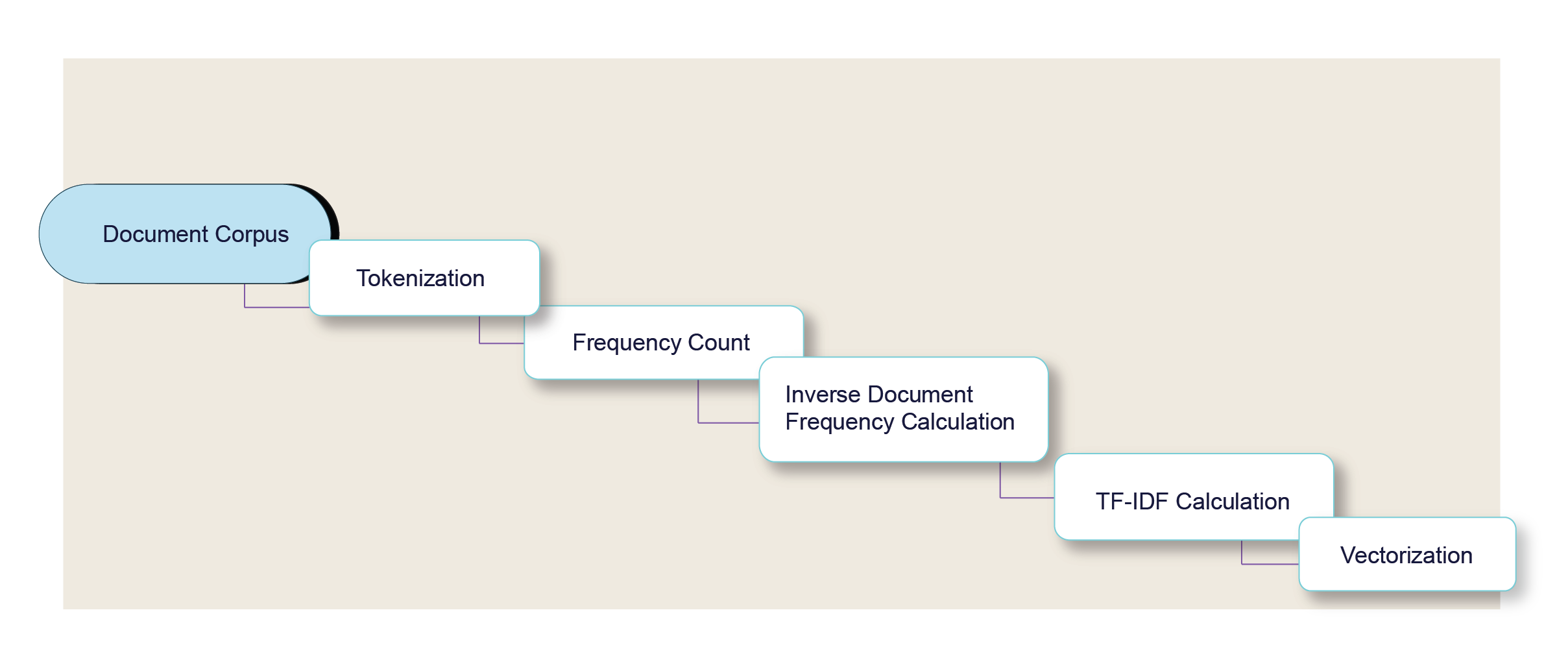
- Count Vectorization: This method, also known as “Bag of Words,” involves counting the frequency of each word in each document in the corpus. The vector for each word then includes these counts. However, it assumes all words are independent of each other, ignoring any sense of order or context, which can be a significant limitation for understanding language.
- TF-IDF (Term Frequency-Inverse Document Frequency): TF-IDF builds upon the count vectorization technique by weighing the word counts by how unique the words are to the given document. Words that appear frequently in one document but not often in the corpus as a whole are given higher weights. This method helps highlight words that are likely to be more relevant to the document, but it still overlooks the context in which words are used.
- Word Embeddings: This technique stands out from the rest due to its ability to capture semantic meanings and relationships between words. Word embeddings, such as Word2Vec, GloVe, and FastText, generate dense vector representations where the vector values are trained to predict the word’s context. Consequently, words that appear in similar contexts have vectors that are closer together, preserving both semantic and syntactic relationships.
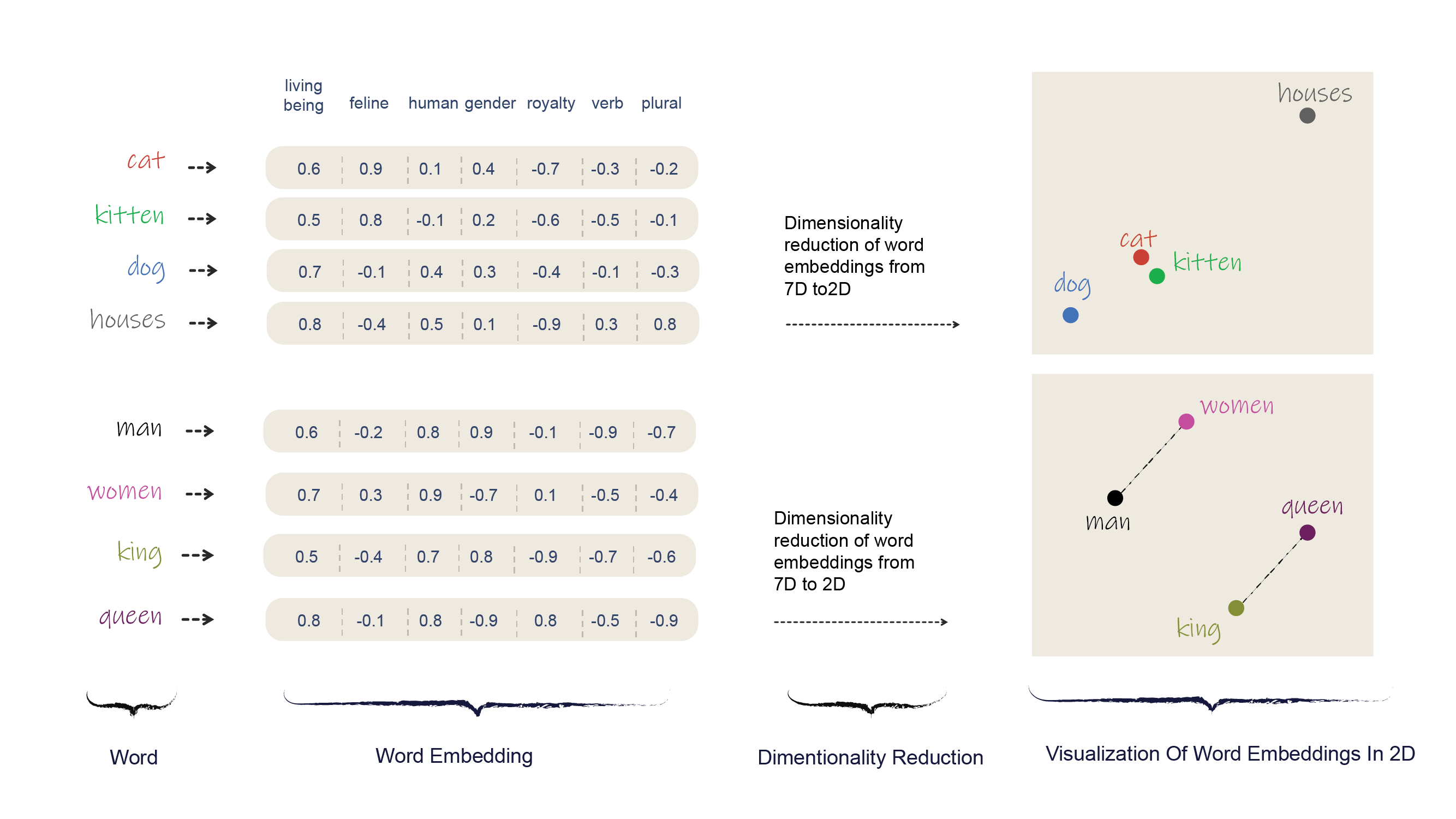
Among these methods, word embeddings have proven to be incredibly effective for many natural language processing tasks. Their power lies in their ability to capture the contextual nuances that are so essential to human language. They map words into a high-dimensional space where the ‘distance’ and ‘direction’ between words encapsulate their relationships, allowing AI models to make more nuanced interpretations of text data.
By positioning words in this high-dimensional space, word vectorization allows AI models to use distance and angle between vectors as a way to interpret word meanings. Closer words in the vector space have more similar meanings than those farther apart. This mapping forms the foundation for natural language understanding in AI, as it allows AI models to grasp the semantic relationships and contextual nuances inherent in human language.
Word vectorization in LLMs
In the early stages of AI and NLP, word vectorization was more static – like having a fixed map of Rome. Each word had its own unique, unchanging place on that map, or a pre-determined vector in the language model.
However, modern LLMs bring a more dynamic approach to the scene. They recognize that language, just like Rome, is not static but constantly changing and evolving. Newer models based on the transformer architecture allow the vector representation of a word to adapt based on its context. It is as if, instead of a static map, you now have a living, breathing city where each street’s (or word’s) significance can change based on the time of day, an event, or the presence of other elements.
Just as the aura of St. Peter’s Basilica in Rome can change between a sacred pilgrimage site during the day and an illuminated spectacle at night, the word ‘bat’ may settle close to ‘baseball’ in one conversation and ‘nocturnal’ in another, altering its position in the map of meanings.
BERT, for instance, employs a technique called Masked Language Modeling. It is like trying to understand Rome by sometimes masking or hiding certain landmarks and trying to infer their existence based on the surrounding architecture. By masking words during training and predicting them based on the surrounding context, BERT learns to understand language in a more nuanced way.
On the other hand, GPT-3.5/4 uses a technique similar to predicting a pedestrian’s next step in Rome based on their current path. It is trained to predict the next word in a sentence, honing its ability to capture the flow and structure of language.
These sophisticated approaches to word vectorization help LLMs produce text that can sometimes be astonishingly human-like. They can maintain a consistent narrative, adjust their writing style, and even exhibit a kind of common-sense reasoning. But as with any model, they have their limitations.
Challenges and Limitations of Word Vectorization
While word vectorization serves as our navigational tool through the complexities of language, there are still challenges that arise. One of the major roadblocks is the management of semantic complexity. Word vectorization methods like Word2Vec and GloVe can discern semantic relationships between words, but they occasionally stumble over understanding the different senses of a word or the delicate nuances that surface in varied contexts. Picture a tour guide who knows the city of Rome like the back of his hand but fumbles when explaining the historical or cultural significance of each site – that’s a linguistic model struggling with semantic complexity.
Understanding synonyms and homonyms presents another obstacle. Much like twins and doppelgängers in a city full of individuals, synonyms (different words with similar meanings) and homonyms (same words with different meanings) can confound word vectorization methods. This is primarily because these methods treat each unique word as a distinct entity, neglecting to consider the semantic similarities or differences.
Some facets of language prove elusive, like hidden corners that resist mapping. Word vectorization methods often find themselves challenged to capture the subtleties of language. For instance, the difference in sentiment between “this is not good” and “this is not bad” may escape them. This is due to the fact these methods typically do not consider the order of words, a critical factor in understanding the meaning of a sentence.
Contextual variations also pose a significant limitation. Traditional word vectorization methods assign a single vector to each word, irrespective of its context. This means that the word “bank” would have the same vector in “I went to the bank” and “I sat on the bank of the river”. This lack of context-sensitivity represents a considerable limitation,as the meaning of a word can shift dramatically based on its context.
Lastly, dealing with rare words and morphological variations can be a challenge. For instance, the words “run” and “running” might be treated as completely different words, ignoring their shared root. Similarly, rare words might not have accurate vector representations because they don’t appear frequently enough in the training data.
Case Studies of Effective Word Vectorization
The power of word vectorization can be seen through its effective application in various sectors. Here are some real-world examples:
- Sentiment Analysis by Amazon: Amazon uses word vectorization to analyze customer reviews for products. This AI-driven approach allows them to sort through thousands of reviews quickly and identify trends in customer sentiment. It has been instrumental in providing actionable insights to sellers and improving the overall customer experience.
- Automated Customer Support by Zendesk: Zendesk, a leading customer service software company, uses word vectorization in their Answer Bot. This AI-driven customer service bot understands customer queries using word vectors and provides relevant solutions or routes the query to a human operator if needed. This has greatly improved their customer response time and efficiency.
- Translation Services by Google: Google Translate employs word vectorization in its translation services, aiding communication across different languages globally. The system understands the context of the source text through word vectors, enabling it to produce more accurate translations than literal word-for-word conversions.
For example, the Spanish phrase “dar gato por liebre,” which literally translates to “give cat for hare,” actually means “to deceive.” By using word vectorization, Google Translate understands the phrase’s contextual meaning and translates it as “to pull a fast one” or “take for a ride,” instead of a nonsensical literal translation.
Current Research and Advancements in Word Vectorization
Advancements in word vectorization are constantly being made, with researchers around the globe pushing the boundaries of what is possible in natural language understanding. Let us delve into some of the latest research in this field.
- Supradiegetic Linguistic Information in LLMs: This study discusses the impressive linguistic fluency achieved by LLMs like ChatGPT. It investigates the current and potential capabilities of these models, emphasizing the profound changes they bring to the field of artificial intelligence. The researchers delve into the intricacies of how these models understand and generate language, exploring their ability to produce coherent and contextually appropriate responses. They also discuss the limitations of these models, such as their inability to access real-world knowledge beyond their training data, and their lack of understanding of the user’s intent.
- Word2Vec-style Vector Arithmetic in LLMs: In this paper, researchers present evidence that despite their size and complexity, LLMs sometimes exploit a computational mechanism familiar from traditional word embeddings: the use of simple vector arithmetic. In simpler terms, they found that these sophisticated models sometimes use a basic mathematical operation to understand and generate language. This is particularly true for tasks that require the model to recall information from its training data. This discovery is encouraging because it suggests that, despite the complexity of these models, the strategies they use to solve tasks can sometimes be simple and intuitive.
- Long Text Analogy Evaluation in LLMs: This paper introduces ANALOGICAL, a novel benchmark for evaluating the quality of LLMs in the context of long text analogy. This research highlights the significant role of analogies as an intrinsic measure for evaluating the quality of these models. The researchers propose a new evaluation metric that focuses on the model’s ability to understand and generate analogies, which is a key aspect of human language understanding.
Conclusion
Language is not just a tool for communication. It is a reflection of who we are, how we think, and how we connect with others. The challenge of fully capturing the richness of our language – with its idioms, cultural references, synonyms, homonyms, and ever-evolving vocabulary – is still an open quest.
Yet, the strides we have made are undeniably significant. From static word embeddings to dynamic, context-sensitive models, the journey thus far has fundamentally changed how machines understand and generate human language. As we refine these techniques and build on these models, we are not just creating smarter machines; we are fostering a deeper understanding of our own language, and, in the process, learning more about ourselves.